Sfide nel ROM Hacking di Chokuretsu– Seguito della Compressione & Archivi
La mia bozza iniziale del post sui file di archivio bin Shade era lungo. Tipo, molto lungo. C'era molta roba che ho dovuto necessariamente tagliare nella versione finale per poter parlare di come ho eseguito il reverse-engineering della struttira dell'archivio e far funzionare il reinserimento dei file. Inoltre, un bel po' di domande chieste frequentemente arrivarono in risposta ai primi due post e spero di poter usare questo post per catalogare le mie risposte ad alcune di esse.
Nessuno Sa Quello Che Fa
Quando iniziai a scrivere il codice sull'archivio, l'ho fatto volendo semplicemente estrarre i file e senza capire nulla della struttura dell archivio bin. Quindi, scrissi del codice che cercava semplicemente per gli spazi tra un file e l'altro per identificare i loro offset. Anche mentre imparavo sempre di più sulla struttura degli archivi, il reverse-engineer degli interi magici, e lavorando nella sostituzione dei file ed eventualmente il loro inserimento, continuai quest'architettura piena di problemi. Impressivamente, questo codice rimase tale fino a quando scrissi il post precedente (lol). Ha causato un bel numero di bug, fui pure in grado di corrompere un file nell'archivio della grafica perché non aveva spazi intorno a sé ed il file precedente (il file precedente finiva circa in 0x7F8 e l'altro iniziava in 0x800).
Credo che il post precedente possa aver dato l'impressione che le cose andarono perfettamente dall'inizio e volevo evidenziare che non è stato assolutamente così. Questo è un processo di prova dopo prova e un insegnamento costante per me – non avevo neanche capito che questi erano archivi mentre ne stavo facendo il reverse-engineering e i stavo invece chiamando "filesystem personalizzati"
Fu così fino a quando Ermii chiese gentilmente se erano file di archivio, e lì realizzai che... sì, erano proprio quelli.
La Lunghezza dei File
Qualcosa di cui non parlai nel post sugli archivi era il fatto che non ho fatto tutto il reverse-engineer dell'intero archivio in una sola volta. Il codice che ho scritto era ad-hoc mentre scoprivo svariate cose qua e là. Ho scoperto gli offset prima ancora di capire che il resto degli interi magici codificavano la lunghezza, quindi stavo rimpiazzando i file negli archivi senza cambiarne la lunghezza. Questo risultò in cose stupende come questa:

Provare a rimpiazzare i file della grafica portava alla corruzione perché la mia routine di compressione risultava meno efficace rispetto a quella che gli sviluppatori avevano utilizzato, il che significa che i file compressi che stavo reinserendo nel gioco erano più lunghi del previsto. Ho passato molto tempo a provare a capire cosa stava succedendo finco a quando non determinai la codificazione della lunghezza dei file.

Molto meglio!
Scrivendo le Prove
Quindi ci furono moltissime prove e moltissimi errori, il che significa che dovevo essere in grado di verificare che cose come i programmi della routine di compressione o il reinserimento dell'archivio funzionassero in maniera consistente. Un modo fantastico di farlo è scrivendo le prove ed è esattamente quello che ho fatto. Ecco una prova per l'implementazione della compressione che ho scritto sotto:
[Test]
[TestCase("evt_000", TestVariables.EVT_000_DECOMPRESSED, TestVariables.EVT_000_COMPRESSED)]
[TestCase("evt_66", TestVariables.EVT_66_DECOMPRESSED, TestVariables.EVT_66_COMPRESSED)]
[TestCase("evt_memorycard", TestVariables.EVT_MEMORYCARD_DECOMPRESSED, TestVariables.EVT_MEMORYCARD_COMPRESSED, false)]
[TestCase("grp_c1a", TestVariables.GRP_C1A_DECOMPRESSED, TestVariables.GRP_C1A_COMPRESSED, false)]
[TestCase("evt_test", TestVariables.EVT_TEST_DECOMPRESSED, TestVariables.GRP_TEST_COMPRESSED)]
[TestCase("grp_test", TestVariables.GRP_TEST_DECOMPRESSED, TestVariables.GRP_TEST_COMPRESSED)]
public void CompressionMethodTest(string filePrefix, string decompressedFile, string originalCompressedFile)
{
byte[] decompressedDataOnDisk = File.ReadAllBytes(decompressedFile);
byte[] compressedData = Helpers.CompressData(decompressedDataOnDisk);
File.WriteAllBytes($".\\inputs\\{filePrefix}_prog_comp.bin", compressedData);
if (!string.IsNullOrEmpty(originalCompressedFile))
{
Console.WriteLine($"Criterio Originale di Compressione: {(double)File.ReadAllBytes(originalCompressedFile).Length / decompressedDataOnDisk.Length * 100}%");
}
Console.WriteLine($"Il Nostro Criterio di Compressione: {(double)compressedData.Length / decompressedDataOnDisk.Length * 100}%");
byte[] decompressedDataInMemory = Helpers.DecompressData(compressedData);
File.WriteAllBytes($".\\inputs\\{filePrefix}_prog_decomp.bin", decompressedDataInMemory);
Assert.AreEqual(StripZeroes(decompressedDataOnDisk), StripZeroes(decompressedDataInMemory), message: "Implementazione Fallita.");
}
Questo test comprime un po' di dati e poi li decomprime per validare che la decompressione dei file è identica a quella originale. Questo fu usato ripetutamente durante il debug della routine di compressione per assicurare che funzionasse mentre ne implementavo ogni parte. A proposito di quello…
La Routine di compressione
Ho avuto un bel po' di domande su come ho implementato la routine di compressione, quindi ho pensato di parlarne un po' qui.
Penso che il processo di base sia semplice da capire: in pratica, stiamo solamente facendo il reverse-engineering di quello che la routine di decompressione fa. Ad esempio, quando decomprimiamo un file, potremmo incontrare un byte con il primo bit a zero ed il secondo impostato (es. 0b01xxxxxx), che stando all'algoritmo del quale abbiamo effettuato il reverse-engineer significa che prendiamo gli ultimi 6 bit e gli aggiungiamo 4, per poi ripetere quel numero un po' di volte (ad esempio, se dovessimo incontrare 43 05 nel buffer di compressione, dovremmo scrivere sette byte 05 nel buffer di decompressione). Quindi, quando lo comprimiamo, dobbiamo cercare per almeno quattro byte ripetuti di fila – se dovessimo incontrare quella ripetizione, allora codifichiamo il byte di controllo seguito dal byte ripeturo (es. se dovessimo incontrare 05 05 05 05 05 05 05 nel buffer decompresso dovremmo scrivere 43 05 nel buffer compresso).
Questo è praticamente l'intero processo. Diventa al quanto complicato per il "dizionario che scivola", una caratteristica della compressione LZ (che io chiamo le retrospezioni nel mio codice). Per quelli, tengo praticamente un dizionario che contiene ogni sequenza di quattro byte nel file e controllo se l'attuale sequenza di quattro byte è nel dizionario. Se lo è, lo inserisco nel codice di controllo per la sequenza della retrospezione nel buffer compresso.
Trovare i Nomi dei File
Ho trascurato un dettaglio importante riguardo l'header dell'archivio – c'è altro oltre alla sezione dell'intero magico! Scorrendo sotto gli interi magici, c'è un'altra sezione della stessa lunghezza di quella precedente e poi un'altra sezione che non aveva una lunghezza ben definita ma i quali elementi sembravano seguire un pattern. Per praticamente l'intero sviluppo degli strumenti per Chokuretsu, ho completamente ignorato queste due sezioni – saltandole letteralmente nel codice.

Mentre stato scrivendo l'ultimo post, stato dando un'altra occhiata a queste due sezioni che ho trovato affascinanti. C'era sicuramente qualcosa qui – all'inizio, commentai che potessero essere i nomi dei file, ma ovviamente non sembravano avere un senso…giusto?
Ora che avevo fatto molti progressi nel progetto, però, avevo molta conoscenza a mia disposizione, ricordai che i file degli eventi avevano dei titoli come EV1_000.
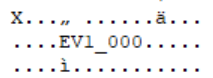
Quindi, decisi di prendere tutti i "nomi dei file" e iniziai a fare un trova/sostituisci in VS Code una lettera per volta. In poco tempo, divenne apparente che questi erano infatti i nomi, semplicemente cifrati. Scrissi velocemente una routine per decifrarli e improvvisamente, navigare tra i file divenne un po' più facile!
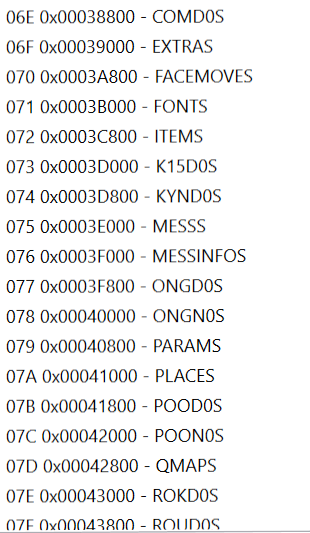
Altre Cose Casuali
La Pazza Routine Della Lunghezza Dei File Rivelata
Un'altra cosa divertente: dopo il secondo post del blog, una persona chiamata Ethanol è entrata nel server Discord di Haroohie e ha buttato una bomba su quello che la routine della lunghezza dei file fa veramente:

Già! Ma ho notato qualcosa del quale non credo sia stata menzionata prima riguardo la “pazza routine della lunghezza dei file”
E ne volevo parlare
Jonko ha semplicemente rifatto una divisione con la sua implementazione :P
La funzione pazza è solo una funzione veloce per dividere gli interi che ha fatto il compilatore
Esatto, è solo una divisione. 🙃 L'ho provata da quella volta ed effettivamente, è proprio quella. Dividere sarebbe stato un po' più veloce rispetto alla mia cosa strana haha.
Seguendo il consiglio del mio editore, vorrei prendere quest'opportunità per scusarmi con gli sviluppatori di Chokuretsu, i quali non stavano, infatti, prendendo per il culo proprio a me questa particolare volta.
Lunghezza Massima Dei File Fissa
Un problema che abbiamo riscontrato subito dopo che abbiamo decodificato l'archivio era che il gioco crashava quando provava a caricare uno dei primi file degli eventi. Come diremo nei prossimi post, i file degli eventi diventeranno sempre più lunghi dopo che li modifichiamo. Dopo molta investigazione, abbiamo scoperto che ci eravamo imbattuti in un problema dove il gioco aveva un valore cablato per la lunghezza massima dei file, che noi stavamo superando. Questa è una cosa completamente al di fuori dell'archivio e codificata come valore costante nel codice del gioco. C'erano quattro posti dov'era codificato, ma eccone uno:
RAM:02033F00 MOV R0, #0x12000
RAM:02033F04 BL sub_202E1C8
In un prossimo post, parleremo di come modifichiamo l'assembly, ma in sintesi questo problema richiedeva una hack di assembly per aggiustarlo poiché abbiamo dovuto modificarlo in una nuova lunghezza massima:
ahook_02033F00:
mov r0, #0x16000
bx lr
Tutto quello che fa è cambiare la lunghezza massima da 0x12000 a 0x16000. Una risoluzione facile, ma allo stesso tempo fastidiosa da trovare!
Ci Vediamo Presto!
Questo è un post più corto, ma volevo assicurarmi di aver parlato di alcune cose che non avevo detto negli scorsi post. Perfavore aspettate il prossimo post della serie che parlerà di come ho fatto il reverse-engineering su certi file di gioco!
Fuyuko è una traduttrice italiana e un'aspirante programmatrice a cui piace la tecnologia dei primi anni 2000.