Sfide nel ROM Hacking di Chokuretsu Parte 2 - Archeologia dell'archivio
L'ultima volta, abbiamo parlato di come ho fatto un reverse-engineering dell'algoritmo di compressione utilizzato in Suzumiya Haruhi no Chokuretsu. Oggi, guarderemo gli archivi che contengono i file di Chokuretsu. Ti chiedo di tenere a mente che mentre io cerco di tenere questi post separati, questo si basa completamente sui concetti fondati la scorsa volta, quindi ti suggerisco di leggerla per prima! Inoltre, se avete già letto lo scorso post, ti avviso che questo è più po' più lungo e contiene più assembly!
Grazie alla proliferazione dei file .zip, sarai già a conoscenza degli archivi: sono file che contengono file, solitamente compressi per risparmiare spazio sul disco. Gli archivi più comuni sono i file .zip, .rar, .7z e .tar.gz. Chokuretsu utilizza un archivio personalizzato con l'estensione .bin. Visto che Shade è lo sviluppatore del gioco, questi file vengono riferiti come "archivi bin Shade" o semplicemente "archivi bin." Iniziamo scegliendo un archivio da guardare.
Per convenienza, prendiamo l'archivio che contiene il file che stavamo guardando la scorsa volta. Possiamo aprire il gioco in CrystalTile2 e navigare fino a dove eravamo arrivati…
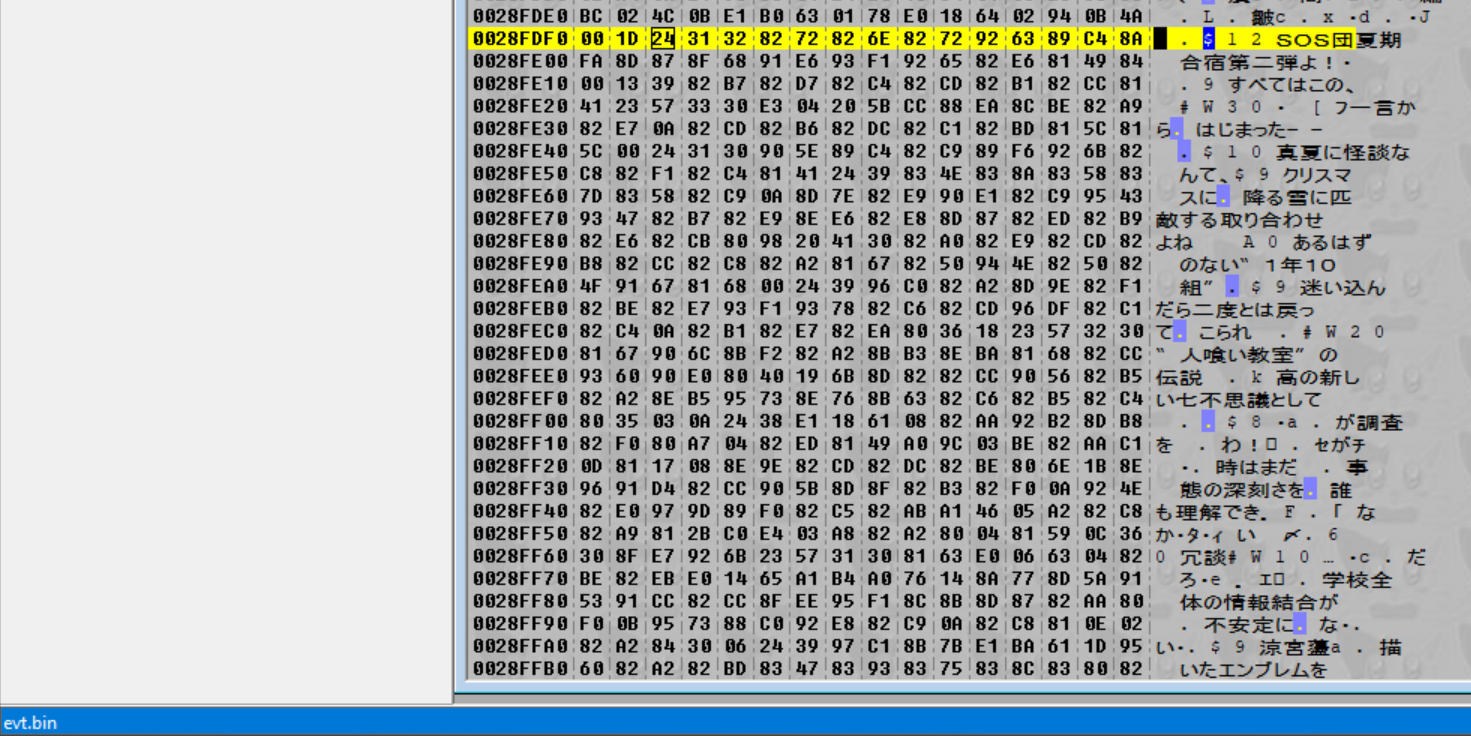
E nell'angolo in basso a sinistra ci dice che questi dati sono contenuti in evt.bin (Il che è quello che avremmo potuto pensare, essendo che questi dati sono delle stringhe).
Esaminare evt.bin
Prima che lo apriamo nell'editor esadecimale, però, parliamo un po' di quello che dovremmo aspettarci di vedere in un archivio (in modo da confermare che evt.bin è infatti un archivio). Ecco gli attributi che gli darei:
- Il numero di file nell'archivio
- Una lista dei file nell'archivio – questa sarebbe composta da i nomi dei file e dagli offset
- I dati di ciascun file
Una breve spiegazione del secondo punto – i nomi dei file sono abbastanza ovvi, ma gli offset sono dei modi per indicare la posizione dei dati in un file. In breve:
- Un indirizzo è la posizione assoluta dei dati in memoria. Quando impostiamo dei breakpoint, utilizziamo gli indirizzi.
- Un offset è la posizione relativa dei dati in un file. Quando abbiamo un singolo file aperto nell'editor esadecimale, parliamo di offset.
- Un puntatore è un valore che punta (indica) un indirizzo o un offset. Un puntatore che indica un indirizzo può sembrare un semplice numero intero come 0x0220B4A8, mentre un puntatore che indica un offset può essere semplice tanto quanto un 0x3800. Gli indirizzi vengono usati dai programmi per accedere alla memoria, mentre gli offset sono utilizzati per i file (visto che non vengono caricati in un punto preciso della memoria), lasciandoli comvertire in indirizzi dal programma stesso.
Quindi, mettendo da parte quello, apriamo evt.bin. Per prima cosa dobbiamo scorrere giù un pochino giusto per capire il layout di questo file…

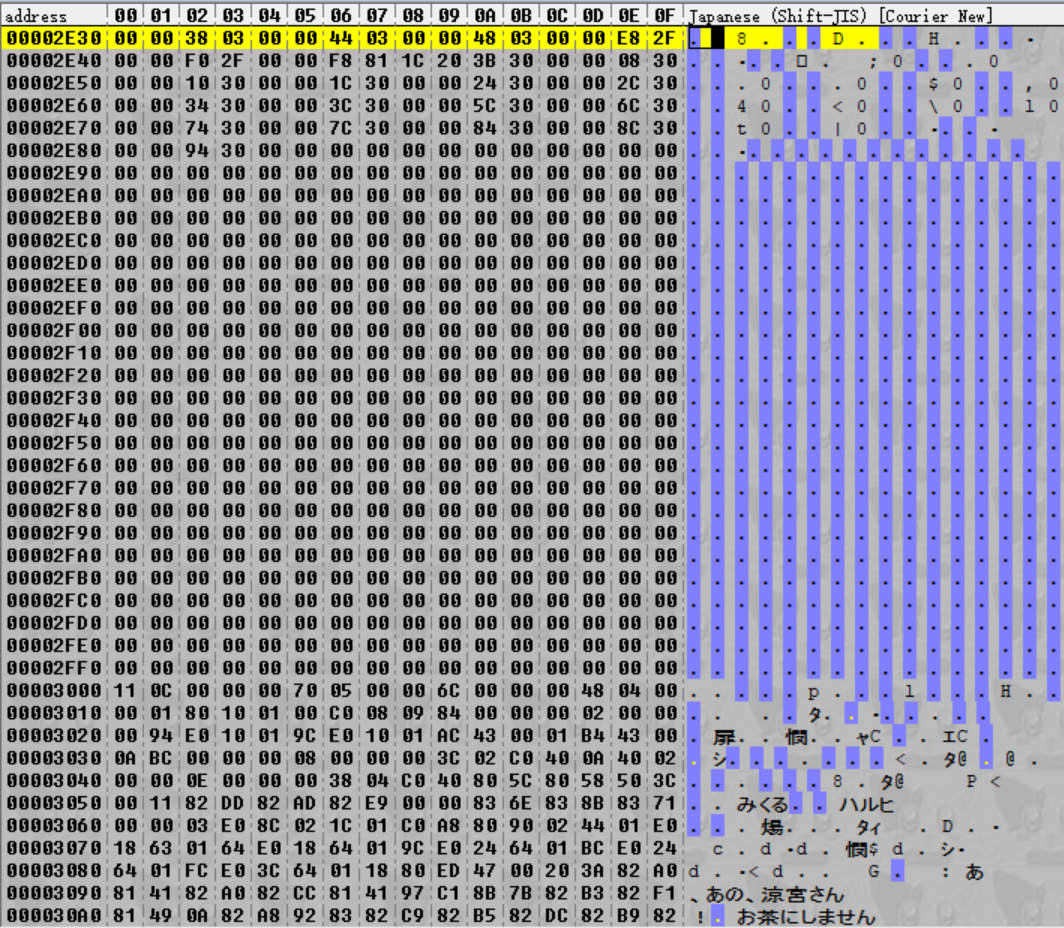
Interessante! Dopo aver scorso un bel pezzo di dati, siamo finiti in un campo di zeri, seguito da un altro grande pezzo di dati seguito da un altro campo di zeri e così via. Inoltre, dopo aver scorso dopo la prima parte, ogni grande pezzo di dati sembra partire dopo un multiplo di 0x800 (un po' difficile da capire dalle immagini ma fidati, apri il file e vedrai il pattern). A me, questi sembrano i dati dei file – e in più, ogni file è separato per bene con molto spazio in mezzo.
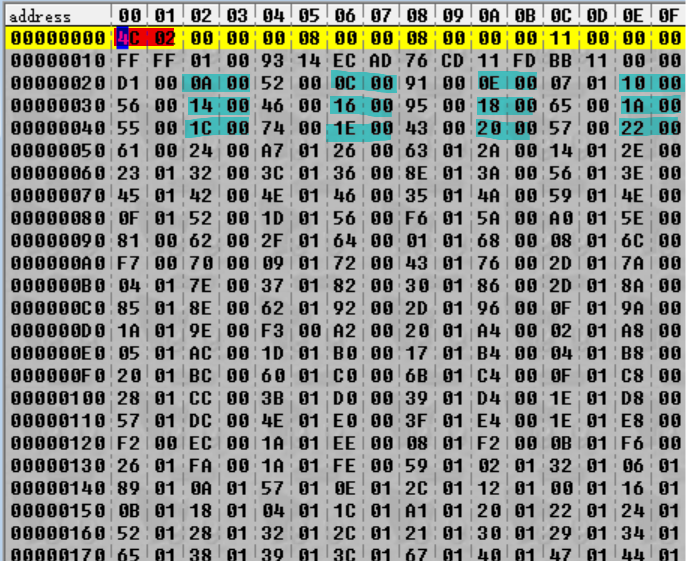
Tornando in cima al file – ancora una volta, un sacco di numeri, ma ci sono dei pattern qui. Ma prima di guardare i numeri in ciano, ecco una breve spiegazione sull'endianità. Fin'ora, abbiamo principalmente pensato a queste in termini di byte, che hanno valori da 0 (0x00) a 255 (0xFF). Ma se dobbiamo invece rappresentare numeri interi più grandi? Per farlo, dobbiamo usare degli interi multi-byte. I tipi più comuni di questi sono:
| Numero di Byte | Nome Formale | Nome in C# |
|---|---|---|
| 2 | interi a 16-bit | short (con segno) or ushort (senza segno) |
| 4 | interi a 32-bit | int (con segno) or uint (senza segno) |
| 8 | interi a 64-bit | long (con segno) or ulong (senza segno) |
Ci sono due modi possibili per inserire un intero a 16-bit, tuttavia. Per esempio, prendi 512 (0x200). Potresti scegliere di metterlo iniziando dal byte più significativo (es. 02 00) o dal byte meno significativo (es. 00 02). Questa decisione è chimata endianità, dove il primo metodo è chiamato "endiano grande" e l'ultimo "endiano piccolo." Frequentemente, la decisione dipende da quello che l'architettura usa; ARM è un'architettura a endiani piccoli, quindi anche questi file saranno probabilmente a endiani piccoli.
Tornando alla parte evidenziata in ciano nell'immagine soprastante, possiamo vedere che se interpretiamo questi valori come degli interi a 16-bit a endiani piccoli, avremo una sequenza del tipo:
0x000A, 0x000C, 0x000E, 0x0010, 0x0014, 0x0016, 0x0018, 0x001A, 0x001C, 0x001E, 0x0020, 0x0022 …
Questi interi aumetano man mano che andiamo avanti! Infatti, continuano a crescere per ben altri 0x900 byte, con il pattern che termina all'intero finale 0x94E:
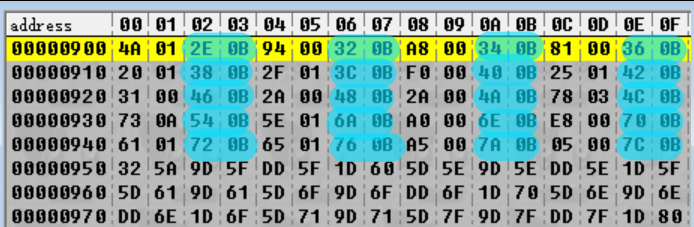
Questi non sono di certo offset dei file (la differenza tra di loro è fin troppo poca – ad esempio, un file tra gli offset 0xB2E e 0xB32 sarebbero lunghi di solo 4 byte). Questo ci indica che forse c'è uno di questi valori per file – quindi quanti ce ne sono? I due valori sono lunghi due byte e sono divisi da due byte per un totale di quattro byte per iterazione. La sequenza inizia a 0x20 e finisce a 0x950. Quindi:
(0x950 - 0x20) / 0x04 = 0x24C
Oh! Guarda un po'! Sembra proprio che 0x24C sia il primo numero ad apparire nel file (evidenziato in rosso). Quindi possiamo credere che il primo numero è il numero dei file nell'archivio. (Per verificarlo, dovremmo controllare che il pattern sia consistente anche negli altri archivi – il che lo è.)
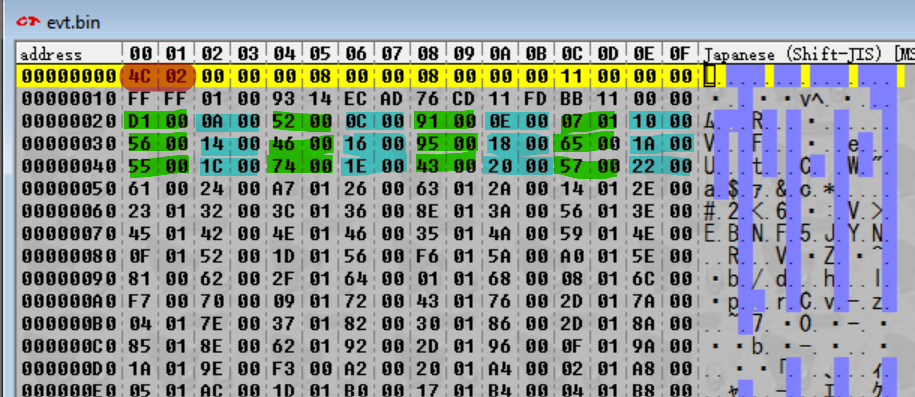
Invece, per quanto riguarda quelli vicini a quelli evidenziati in ciano – quelli verdi evidenziati di sopra? È difficile da capire adesso poiché non c'è nessun pattern ovvio. Tuttavia, abbiamo bisogno di un po' di nomenclatura qui, quindi mi riferirò alla combinazione delle parti evidenziate in verde e ciano come interi magici, visto che sono offuscati (magia) ma fanno anche della roba importante (altra magia). Il primo intero magico ha un intervallo da 0x20 a 0x23, questo è il motivo per i quali sono "interi" – più nello specifico, interi a 32-bit.
Nel dettaglio, Ripresa
Lo scopo della sezione precedente era quello di dimostrare come a) identificare che un file è un archivio e b) usare un pattern basilare per effettuare un reverse-engineering su un archivio. Tuttavia, questo archivio è un po'strano e offuscato – mentre la maggior parte degli archivi in cima contengono i nomi dei file e i loro offset (posizione nell'archivio) per ogni file, non è di certo il caso con questo. Tutte quelle informazioni sono in qualche modo nascoste. Ci sono vari modi per avere a che fare con una cosa del genere, ma per me, l'opzione più facile è sembrata quella di tornare all'assembly.
Caricamento Tabella dei File
Per prima cosa, dobbiamo trovare il codice che analizza questi archivi. Per farlo, dobbiamo andare attraverso lo stesso processo della scorsa volta – faremo una ricerca nella memoria per l'intestazione (header, l'inizio del file, prima ancora dei file nell'archivio) dell'archivio, impostare un punto d'interruzione (breakpoint), e vedere come viene interpretata l'intestazione.
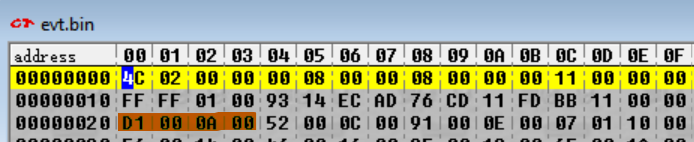
Quindi, torniamo in DeSmuME e cerchaimo per i byte nell'offset 0x20 (ricorda, DeSmuME si aspetta che nella ricerca nella memoria i byte vengano inseriti nell'ordine inverso, quindi al posto di D1 00 0A 00 inseriremo 00 0A 00 D1)...
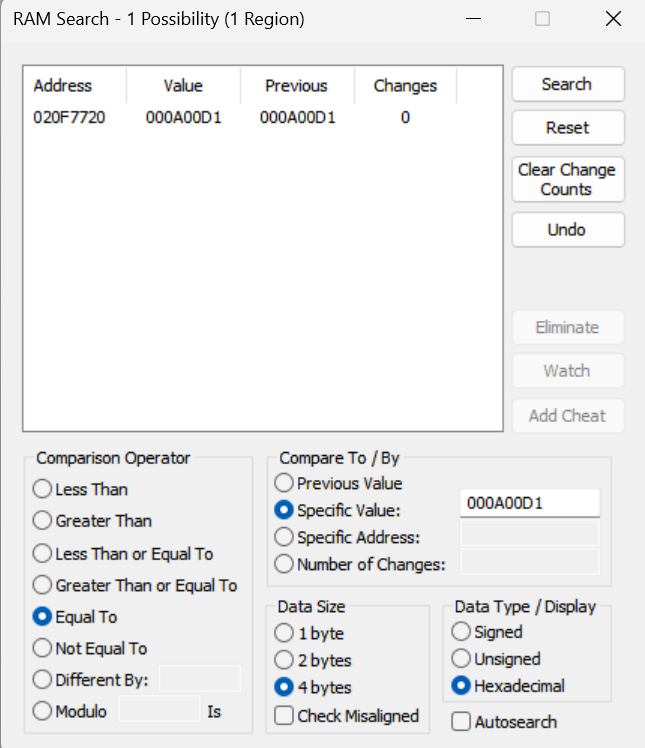
E ancora una volta, abbiamo un singolo risultato. Quindi apriamo il visualizzatore di memoria in 0x020F7720…
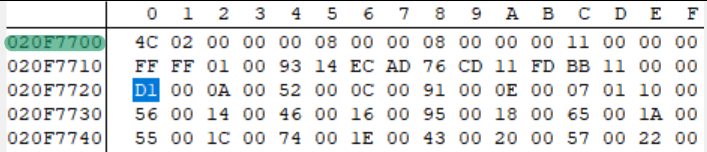
Ed è esattamente identico all'intestazione di evt.bin! Questo significa che l'intestazione di evt.bin è caricata in 0x020F7700. Quindi adesso caricheremo il gioco su no$GBA (la scorsa volta sono stato un po' duro su no$, ma i suoi strumenti di debug sono molto convenienti) e impostiamo un punto d'interruzione in 0x020F7700.
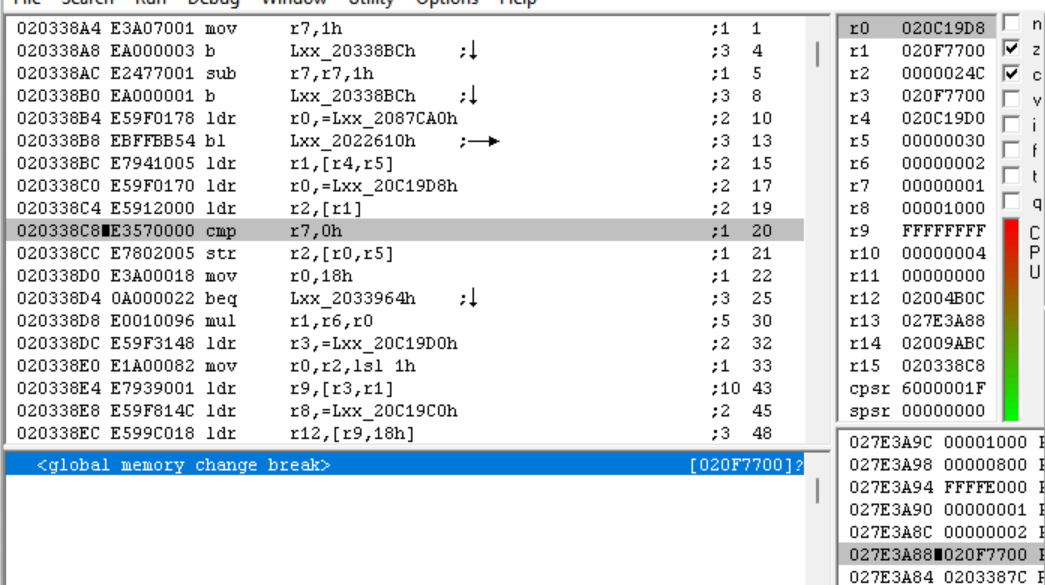
Bene, abbiamo trovato il punto d'interruzione nel momento stesso in cui abbiamo caricato il gioco. questo significa che le intestazioni degli archivi sono caricati all'avvio. Prendiamo questa subroutine in IDA.
RAM:02033818 PUSH {R3-R9,LR}
RAM:0203381C LDR R2, =dword_20A9AB0
RAM:02033820 MOV R6, R0
RAM:02033824 LDR R1, [R2]
RAM:02033828 LDR R0, =aFiletblLoadSta ; "--- filetbl_load start <%d> ---\n"
RAM:0203382C ADD R1, R1, #0x3F ; '?'
RAM:02033830 BIC R3, R1, #0x3F
RAM:02033834 MOV R1, R6
RAM:02033838 STR R3, [R2]
RAM:0203383C BL dbg_print20228DC
Ecco qualcosa di utile! Quella stringa che contiene "--- filetbl_load start <%d> ---\n" è un testo programmato nell'eseguibile del programma (arm9.bin) stesso.
=aFiletblLoadSta è un nome che IDA dà all'indirizzo che contiene quella stringa, quindi LDR R0, =aFiletblLoadSta sta caricando l'indirizzo della stringa in R0. nell'ARM assembly, R0 è il primo parametro utilizzato quando si chiama un'altra subroutine, quindi il BL (branch-link o “chiama questa subroutine”) di sotto lo utilizza come parametro. Poiché questa stringa ha l'aspetto di una stringa di debug, possiamo pensare che sia usata in una funzione di debug di stampa (una funzione che scrive del testo nella console per scopi di debug), quindi rinominiamo la funzione in dbg_print20228DC.
Ma soprattutto, il fatto che questa stringa di debug viene stampata ci dice qual'era il nome originale della funzione nel codice sorgente originale: filetbl_load(). Da qui, possiamo assumere che questa funzione è pensata per caricare la "tabella dei file" dall'archivio – es., carica l'intestazione del file, che contiene tutti i nomi dei file proprio come avevamo pensato! Questo trucchetto (guardare alle stringhe di debug o degli errori per capire quello che una funzione fa) è qualcosa che faccio frequentemente – senza neanche esaminare il disassembly nel dettaglio, ora abbiamo una buona idea di cosa questa funzione fa.
Caricare gli Interi Magici
Dopo aver provato ad analizzare questa routine nello stesso modo della routine di decompressione abbiamo scoperto che questa routine è un po'più astratta. Si riferisce a svariati indirizzi di memoria e altre cose di cui non ne ho il contesto – quindi andiamo a scoprirlo e vediamo quello che fa nel debugger. Dopotutto, il nostro obiettivo non è necessariamente quello di effettuare un reverse-engineering su quello che questa routine fa (al contrario della routine di decompressione), la utilizziamo per capire la struttura del file di archivio.
Quindi torniamo no$GBA. Andando avanti, arriviamo a questa funzione STR. STR R2,[R0, R5] dovrebbe contenere tutti i valori di R2 (0x24C, quello che sospettiamo sia il numero dei file) nella posizione in memoria R0+R5.
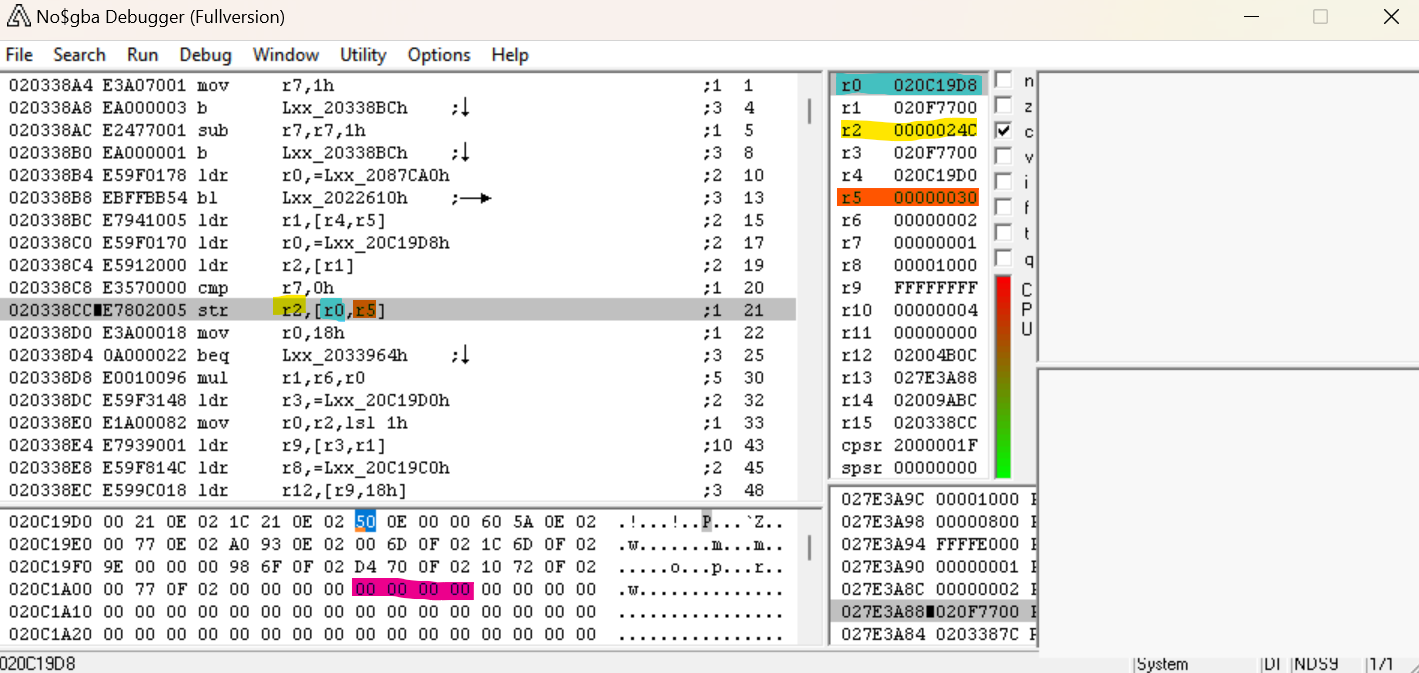
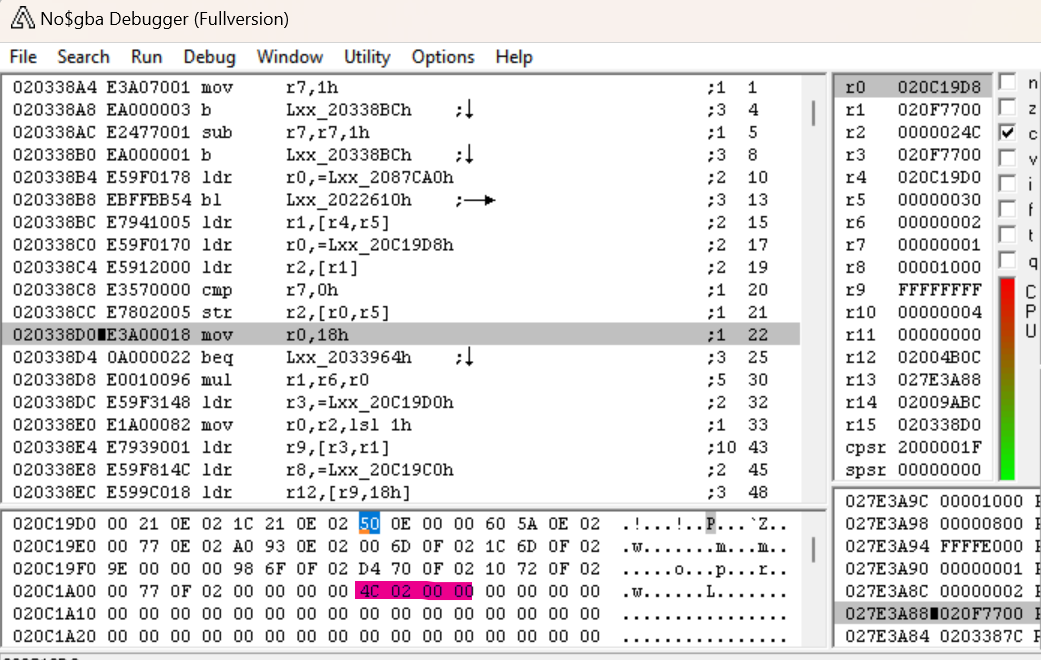
Dopo che sorpassiamo quella istruzione, possiamo infatti vedere che 0x24C è stato messo in 0x20C1A08 come ci aspettavamo. Quindi ora, impostiamo un punto d'interruzione per quell'indirizzo per vedere dove questo viene riferito.
Facciamo partire il gioco…
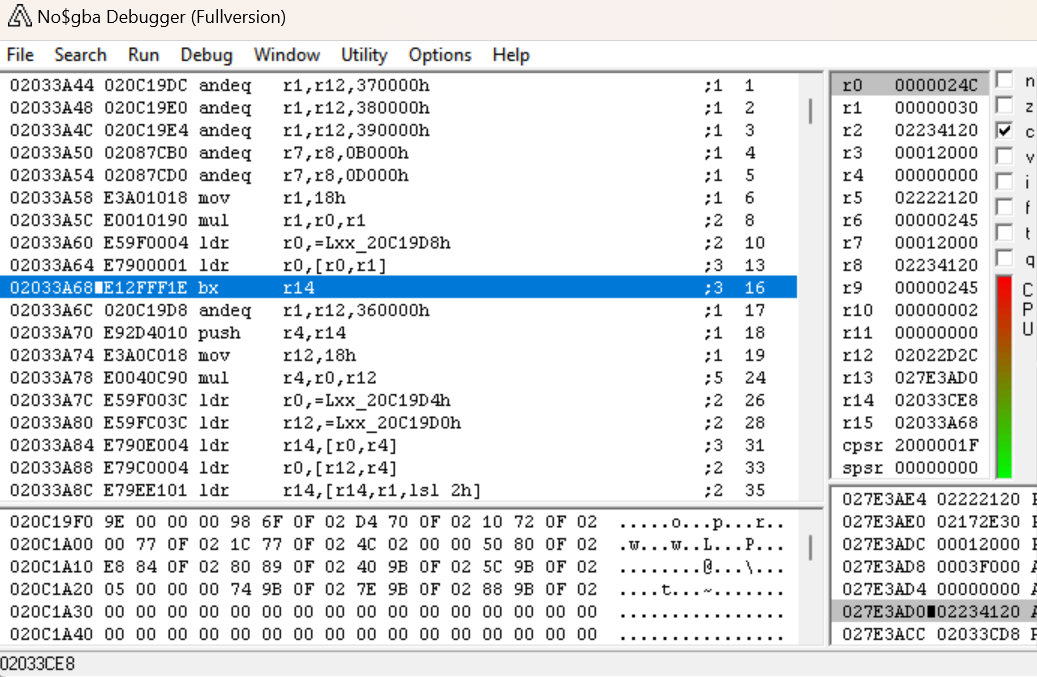
E finiamo in questa nuova routine. Navigare questa routine in IDA ci rivela che è molto corta.
RAM:02033A58 sub_2033A58
RAM:02033A58 MOV R1, #0x18
RAM:02033A5C MUL R1, R0, R1
RAM:02033A60 LDR R0, =dword_20C19D8
RAM:02033A64 LDR R0, [R0,R1]
RAM:02033A68 BX LR
BX LR ci fa tornare alla subroutine che ha chiamato questa, quindi tenendo a mente che sappiamo che l'istruzione precedente è quella di 0x24C caricata in R0 (il registro frequentemente utilizzato come valore di restituzione), potremmo essere in grado di postulare che l'intero scopo di questa subroutine è quella di caricare quel valore nella memoria. Quindi, rinominiamo questa funzione in arc_getNumFiles e vediamo cosa l'ha chiamata.
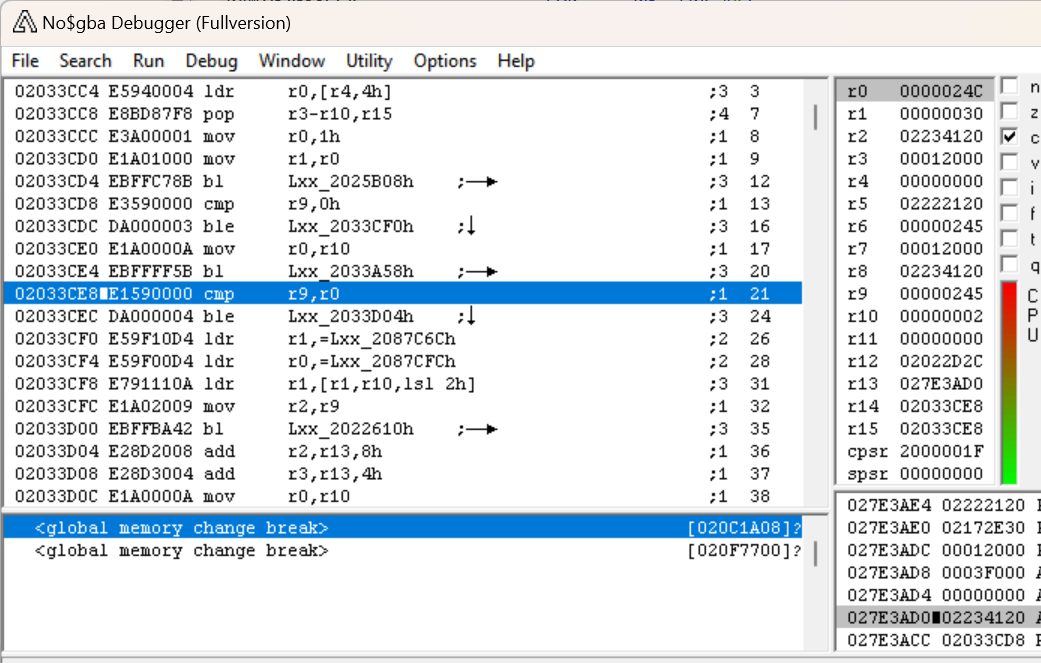
Apriamo questa sezione della subroutine in IDA:
RAM:02033CCC loc_2033CCC
RAM:02033CCC MOV R0, #1
RAM:02033CD0 MOV R1, R0
RAM:02033CD4 BL sub_2025B08
RAM:02033CD8 CMP R9, #0
RAM:02033CDC BLE loc_2033CF0
RAM:02033CE0 MOV R0, R10
RAM:02033CE4 BL arc_getNumFiles
RAM:02033CE8 CMP R9, R0
RAM:02033CEC BLE loc_02033D04
RAM:02033CF0
RAM:02033CF0 loc_2033CF0
RAM:02033CF0 LDR R1, =sArchiveFileNames
RAM:02033CF4 LDR R0, =aFileIndexError ; "errore indice file : [%s],idx=%d\n"
RAM:02033CF8 LDR R1, [R1,R10,LSL#2]
RAM:02033CFC MOV R2, R9
RAM:02033D00 BL dbg_printError
Ricordando che uscendo da arc_getNumFiles, R0 era impostato nel valore (che crediamo sia) il numero dei file. Possiamo vedere che viene confrontato con R9 subito dopo, e se è minore o uguale a R9, lo diramiamo dopo la fine della sezione che ho appena mostrato. Quindi azzeriamo R9 – guardando quello che c'è in alto, possiamo vedere che R9 è anche confrontato con 0, e se è minore o uguale a 0 lo diramiamo su loc_2033CF0. È lo stesso punto in cui andiamo se R9 è più grande di R0. Se esaminiamo quella sezione, possiamo vedere un altro messaggio di debug – "file index error : [%s],idx=%d\n"! Per coloro che non sono a conoscenza del linguaggio C, questa è un formato stringa – i %s e %d indicano i parametri da inserire nella stringa. %s si aspetta una stringa e %d si aspetta un numero decimale. Abbiamo determinato che la funzione che il BL sta diramando manda una funzione di “stampa del messaggio di errore di debug” dal fatto che la stringa indica che c'è un errore, ma questa stringa ci dà molti più indizi. Quindi in un alto livello, questa sezione controlla se R9 è più grande di 0 e minore o uguale al numero dei file. se non lo è, dà un errore.
Quando si chiama una funzione in un linguaggio di alto livello, si devono specificare i parametri che vengono passati alla funzione. Nell'ARM assembly, questi parametri sono passati impostando dei registri specifici a dei valori specifici – il primo parametro è impostato a R0, il secondo è impostato a R1, ecc. Quindi, sappiamo che questa subroutine dbg_printError stamperà quella stringa formattata. La stringa in questione è caricata in R0, il che significa che il primo parametro è la stringa stessa. Il parametro seguente (corrispondente a %s) dovrebbe essere caricato in R1, e l'ultimo parametro (corrispondente a %d) dovrebbe essere caricato in R2.
Ho già segnato il valore caricato in R1 con il nome =sArchiveFileNames - se noi prendessimo quell'indirizzo in IDA, possiamo vedere il perché:

È una lista dei nomi dei nostri quattro archivi! Quindi quella linea che dice LDR R1,[R1, R10, LSL#2] caricherà nel nome dell'archivio. Se diamo un'occhiata ad R10 nello screenshot di prima, possiamo vedere che è impostato a 2. Solitamente, gli array iniziano da 0, il che significa che l'elemento 2 sarà aEvtBin – EVT.BIN è il valore di %s!
La prossima linea è MOV R2,R9 che sposterà il valore di R9 (il nostro precedente resitro d'interesse) in R2. Dal testo del messaggio di errore, possiamo concludere che R9 contiene l'indice di file, che è la posizione del file che stiamo caricando nell'archivio! Sappiamo anche che il valore che pensavamo che fosse il numero di file nell'archivio era proprio quello. Inoltre, basandoci sulle condizioni che ci hanno portati a quel messaggio di errore, possiamo anche concludere che gli indici partono da 1 e che finiscono alla lunchezza dell'archivio (invece di iniziare da 0 e finire alla lunghezza - 1 che è molto più comune nei computer).
Analizzare l'Intero Magico
Continuiamo:
RAM:02033D04 loc_2033D04
RAM:02033D04 ADD R2, SP, #8
RAM:02033D08 ADD R3, SP, #4
RAM:02033D0C MOV R0, R10
RAM:02033D10 MOV R1, R9
RAM:02033D14 BL sub_2033A70
Stiamo chiamando sub_2033A70 con i seguenti parametri:
- R0: Il numero di archivio (2 =
evt.bin) - R1: L'indice dei file nell'archivio
- R2: Un indirizzo
- R3: Un altro indirizzo
In altre parole:
sub_2033A70(2, 0x24C, address1, address2)
Andiamo a vedere sub_2033A70.
RAM:02033A70 PUSH {R4,LR}
RAM:02033A74 MOV R12, #0x18
RAM:02033A78 MUL R4, R0, R12
RAM:02033A7C LDR R0, =dword_20C19D4
RAM:02033A80 LDR R12, =dword_20C19D0
RAM:02033A84 LDR LR, [R0,R4]
RAM:02033A88 LDR R0, [R12,R4]
RAM:02033A8C LDR LR, [LR,R1,LSL#2]
RAM:02033A90 LDR R1, [R0,#0xC]
RAM:02033A94 LDR R0, [R0,#4]
RAM:02033A98 MOV R1, LR,LSR R1
RAM:02033A9C MUL R0, R1, R0
RAM:02033AA0 STR R0, [R2]
RAM:02033AA4 LDR R0, [R12,R4]
RAM:02033AA8 LDR R1, [R0,#0x10]
RAM:02033AAC LDR R0, [R0,#8]
RAM:02033AB0 AND R1, LR, R1
RAM:02033AB4 MUL R0, R1, R0
RAM:02033AB8 STR R0, [R3]
RAM:02033ABC POP {R4,PC}
Questa subroutine non è troppo lunga, quindi dovremmo essere in grado di capire cosa sta facendo; tuttavia, ci sono molti pezzetti dove carica qualche indirizzo di memoria, e non so cosa contengano quegli indirizzi. Quindi torniamo nel debugger.
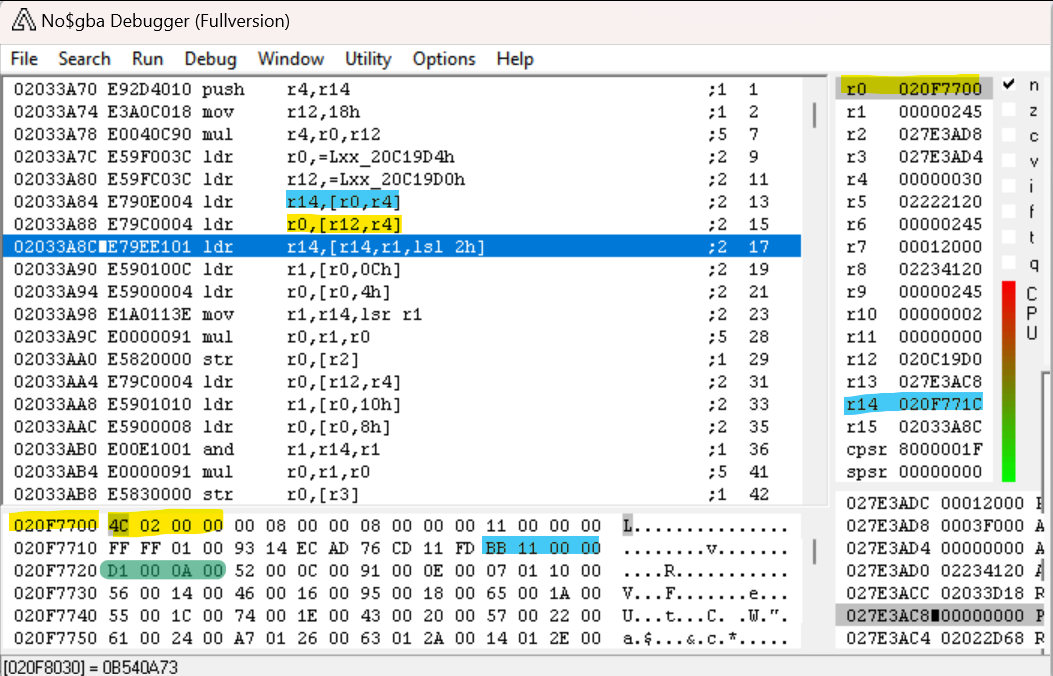
Dopo aver eseguito questi passaggi, possiamo vedere che la prima parte di questa subroutine serve solo a caricare l'indirizzo dell'header di evt.bin che avevamo già trovato in R0. Sta anche impostando LR (Che è chiamato R14 in no$) nell'indirizzo (evidenziato in ciano) subito prima del primo intero magico (evidenziato in verde). Interessante! L'indirizzo attualmente evidenziato è LDR LR, [LR,R1,LSL#2] – questo caricherà il valore nell'indirizzo LR + R1 * 4 in LR. R1, bisogna ricordare, è l'indice del file. Quindi, questo caricherà l'intero magico che corrisponde al file di quell'indice! (Tenete presente che l'array dell'intero magico parte da 1 invece che 0, quindi per farlo partire da 0 dobbiamo partire dall'indirizzo subito prima del primo intero magico.)
In C#, lo possiamo rappresentare così:
public void sub_2033A70(int archiveNumber, int index, uint address1, uint address2, byte[] archiveBytes)
{
int numFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
uint magicInteger = BitConverter.ToUInt32(archiveBytes.Skip(0x1C + index * 4).Take(4).ToArray());
}
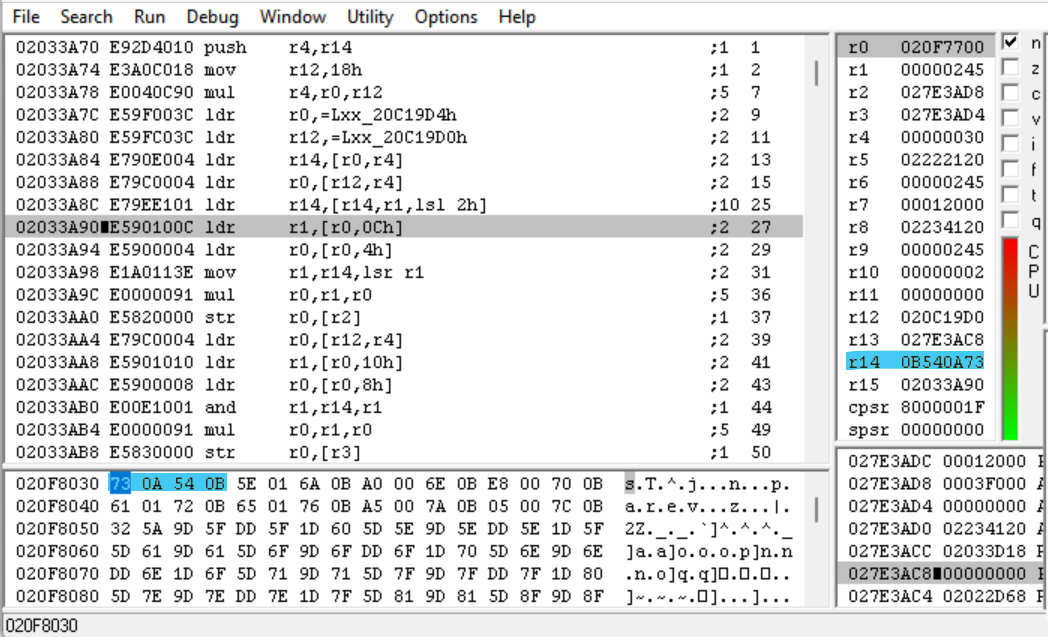
L'indirizzo che dobbiamo caricare è 0x030F771C + 0x245 * 4 = 0x20F8030, e naturalmente, quando lo facciamo vediamo quel valore caricato. Ora che l'intero magico è caricato, vediamo cosa succede dopo.
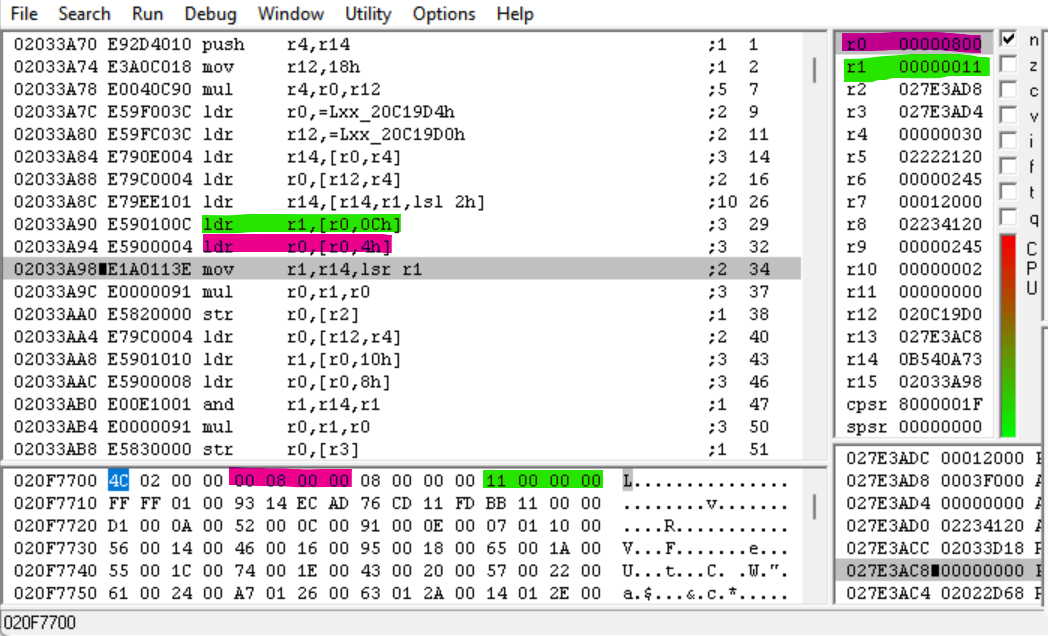
Le prossime due istruzioni caricano gli interi negli offset 0x0C (verde) e 0x04 (rosa) da evt.bin in R1 ed R0, rispettivamente. Queste istruzioni sono poi utilizzate in alcuni calcoli:
MOV R1, LR,LSR R1– Questa istruzione sposta l'intero magico a destra in base al valore di R1 (0x11 o 17) e salva il risultato in R1. Visto che gli interi magici sono interi a 32-bit, questo ci dà i 15 bit più importanti dell'intero magico.MUL R0, R1, R0– Questa istruzione moltiplica R1 per R0 (0x800) e salva il risultato in R0.
Continuando la nostra traduzione in C#, abbiamo:
public void sub_2033A70(int archiveNumber, int index, uint address1, uint address2, byte[] archiveBytes)
{
int numFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
uint magicInteger = BitConverter.ToUInt32(archiveBytes.Skip(0x1C + index * 4).Take(4).ToArray());
int msbShift = BitConverter.ToUInt32(archiveBytes.Skip(0x0C).Take(4).ToArray());
int msbMultiplier = BitConverter.ToUInt32(archiveBytes.Skip(0x04).Take(4).ToArray());
uint value1 = (magicInteger >> msbShift) * msbMultiplier;
}
Dopo aver eseguito queste due istruzioni…
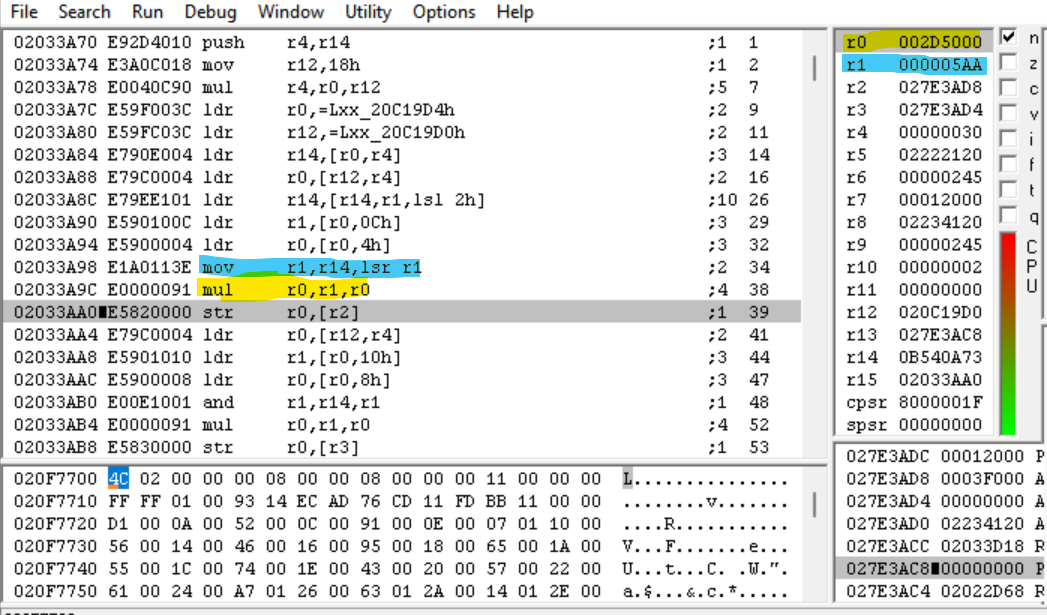
Il valore di R0 è ora 0x2D5000. Aspetta un secondo – abbiamo appena moltiplicato la parte superiore dell'intero magico (quella che abbiamo visto crescere costantemente) per 0x800 (per il quale ogni offset è divisibile). Potremmo aver appena calcolato l'offset di un file?
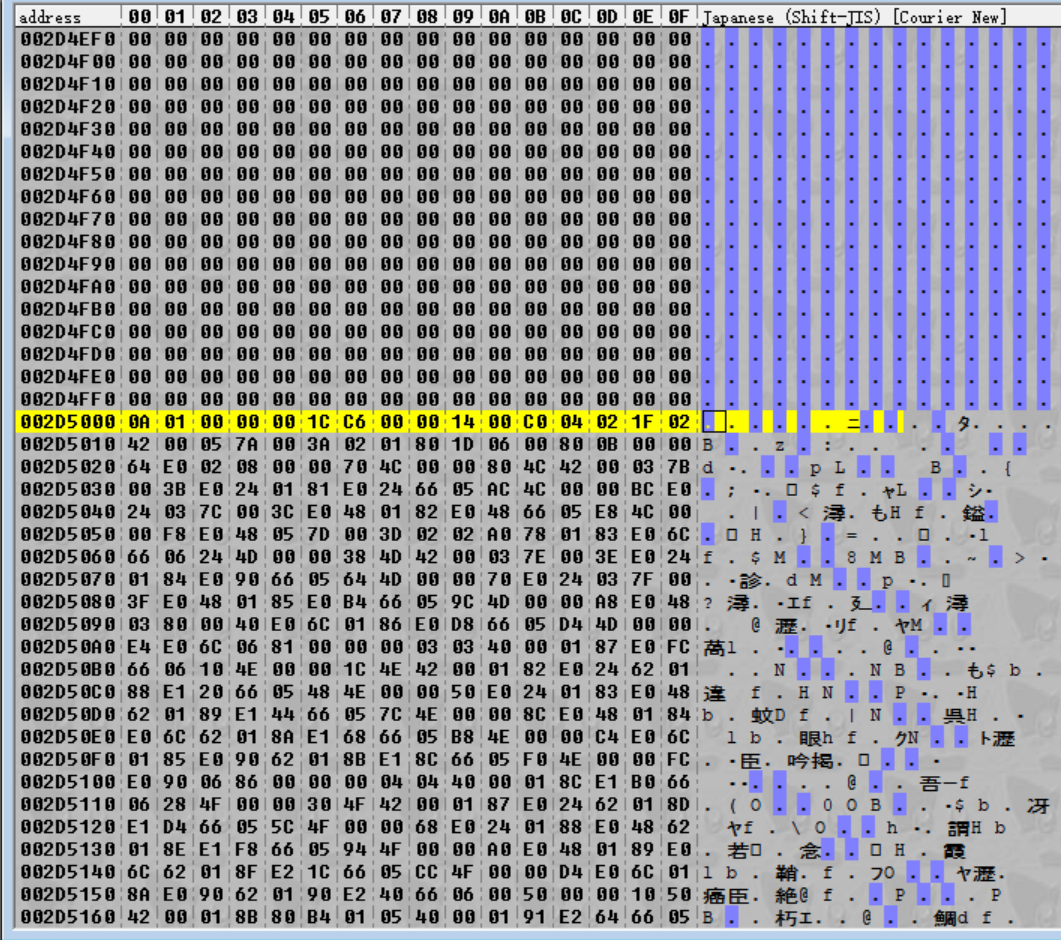
Lo abbiamo proprio fatto! Abbiamo appena trovato la routine per calcolare l'offset di un file dandogli un indice! Ma l'intero magico non è ancora caricato in LR, quindi non abbiamo ancora finito di utilizzarlo.
La prossima istruzione contiene il nostro offset appena calcolato in memoria. L'istruzione dopo carica l'indirizzo di partenza dell'header di evt.bin di nuovo. Adesso abbiamo due istruzioni che sono simili a quelle che abbiamo visto prima.

Questa volta, caricheremo i valori degli offset 0x10 e 0x08 in R1 ed R0, rispettivamente. Ancora una volta, utilizzeremo questi valori per fare un po' di matematica con l'intero magico.
AND R1, LR, R1– questa operazione sta facendo un bitwise-and tra i contenuti di R1 (0x1FFFF) e l'intero magico. Questo ci dà i 17 bit meno importanti dell'intero magico (i complementi dei 15 bit più importanti che abbiamo calcolato sopra).MUL R0, R1, R0– questa istruzione moltiplica R1 per R0 (0x08) e inserisce il risultato in R0.
In C#:
public void sub_2033A70(int archiveNumber, int index, uint address1, uint address2, byte[] archiveBytes)
{
int numFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
uint magicInteger = BitConverter.ToUInt32(archiveBytes.Skip(0x1C + index * 4).Take(4).ToArray());
int msbShift = BitConverter.ToInt32(archiveBytes.Skip(0x0C).Take(4).ToArray());
int msbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x04).Take(4).ToArray());
uint offset = (uint)((magicInteger >> msbShift) * msbMultiplier);
int lsbBitwiseAnd = BitConverter.ToInt32(archiveBytes.Skip(0x10).Take(4).ToArray());
int lsbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x08).Take(4).ToArray());
uint value2 = (uint)((magicInteger & lsbBitwiseAnd) * lsbMultiplier);
}
Il risultato finale di questo calcolo è 0x5398.
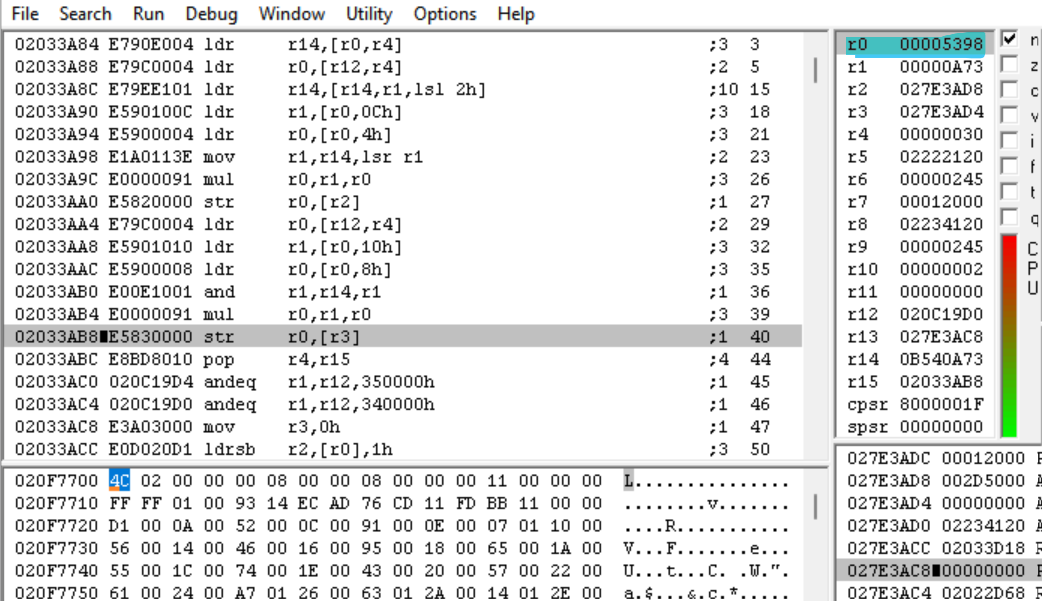
E questa è la fine della funzione. Quindi ora abbiamo trovato l'offset, ma cos'è quel 0x5398? Torniamo nella funzione di chiamata in IDA e vediamo se riusciamo a scoprirlo.
RAM:02033D04 ADD R2, SP, #0x30+var_28
RAM:02033D08 ADD R3, SP, #0x30+var_2C
RAM:02033D0C MOV R0, R10
RAM:02033D10 MOV R1, R9
RAM:02033D14 BL arc_processMagicInteger
RAM:02033D18 MOV R0, #0x18
RAM:02033D1C MUL R1, R10, R0
RAM:02033D20 LDR R0, =dword_20C19D0
RAM:02033D24 LDR R6, [SP,#0x30+var_2C]
RAM:02033D28 LDR R0, [R0,R1]
RAM:02033D2C LDR R5, [R0,#4]
RAM:02033D30 ADD R0, R6, R5
RAM:02033D34 MOV R1, R5
RAM:02033D38 SUB R0, R0, #1
RAM:02033D3C BL sub_201D310
RAM:02033D40 MUL R4, R5, R0
RAM:02033D44 ADD R0, R6, #0xFF
RAM:02033D48 ADD R1, R0, #0x300
RAM:02033D4C MOV R0, R1,ASR#9
RAM:02033D50 ADD R0, R1, R0,LSR#22
RAM:02033D54 MOV R0, R0,ASR#10
RAM:02033D58 STR R0, [SP,#0x30+var_30]
RAM:02033D5C LDR R1, =sArchiveFileNames
RAM:02033D60 LDR R0, =aReadSIdxDOfs0x ; "read:[%s],idx=%d,ofs=0x%x,sz=%dKB"
RAM:02033D64 LDR R1, [R1,R10,LSL#2]
RAM:02033D68 LDR R3, [SP,#0x30+var_28]
RAM:02033D6C MOV R2, R9
RAM:02033D70 BL dbg_print20228DC
Nota le ultime cinque stringhe di debug ("read:[%s],idx=%d,ofs=0x%x,sz=%dKB"). Dopo che l'intero magico viene processato, abbiamo una stringa di debug che fa esplicitamente riferimento all'indice del file, il suo offset, e la sua dimensione. Tuttavia, 0x5398 non è la lunghezza di questo file (sappiamo il suo offset, quindi possiamo controllare la sua lunghezza manualmente; incluso il riempimento, il file è 0x5800 byte in lunghezza). Quindi diamo un'occhiata a quella chiamata delle subroutine tra arc_processMagicInteger e quella stringa di debug: sub_201D310.
La Pazza Routine Per La Lunghezza Dei File
Fai attenzione, questa parte è abbastanza lunga. Non preoccuparti in caso non dovessi capire tutto, non è così importante per lo scopo di questo articolo. È una maniera estremamente offuscata per determinare la lunghezza di un file.
RAM:0201D310 CMP R1, #0
RAM:0201D314 BXEQ LR
RAM:0201D318 CMP R0, R1
RAM:0201D31C MOVCC R1, R0
RAM:0201D320 MOVCC R0, #0
RAM:0201D324 BXCC LR
RAM:0201D328 MOV R2, #0x1C
RAM:0201D32C MOV R3, R0,LSR#4
RAM:0201D330 CMP R1, R3,LSR#12
RAM:0201D334 SUBLE R2, R2, #0x10
RAM:0201D338 MOVLE R3, R3,LSR#16
RAM:0201D33C CMP R1, R3,LSR#4
RAM:0201D340 SUBLE R2, R2, #8
RAM:0201D344 MOVLE R3, R3,LSR#8
RAM:0201D348 CMP R1, R3
RAM:0201D34C SUBLE R2, R2, #4
RAM:0201D350 MOVLE R3, R3,LSR#4
RAM:0201D354 MOV R0, R0,LSL R2
RAM:0201D358 RSB R1, R1, #0
RAM:0201D35C ADDS R0, R0, R0
RAM:0201D360 ADD R2, R2, R2,LSL#1
RAM:0201D364 ADD PC, PC, R2,LSL#2
RAM:0201D368 ; ---------------------------------------------------------------------------
RAM:0201D368 NOP
RAM:0201D36C
RAM:0201D36C loc_201D36C
RAM:0201D36C ADCS R3, R1, R3,LSL#1
RAM:0201D370 SUBCC R3, R3, R1
RAM:0201D374 ADCS R0, R0, R0
RAM:0201D378 ADCS R3, R1, R3,LSL#1
RAM:0201D37C SUBCC R3, R3, R1
RAM:0201D380 ADCS R0, R0, R0
RAM:0201D384 ADCS R3, R1, R3,LSL#1
RAM:0201D388 SUBCC R3, R3, R1
RAM:0201D38C ADCS R0, R0, R0
RAM:0201D390 ADCS R3, R1, R3,LSL#1
RAM:0201D394 SUBCC R3, R3, R1
RAM:0201D398 ADCS R0, R0, R0
RAM:0201D39C ADCS R3, R1, R3,LSL#1
RAM:0201D3A0 SUBCC R3, R3, R1
RAM:0201D3A4 ADCS R0, R0, R0
RAM:0201D3A8 ADCS R3, R1, R3,LSL#1
RAM:0201D3AC SUBCC R3, R3, R1
RAM:0201D3B0 ADCS R0, R0, R0
RAM:0201D3B4 ADCS R3, R1, R3,LSL#1
RAM:0201D3B8 SUBCC R3, R3, R1
RAM:0201D3BC ADCS R0, R0, R0
RAM:0201D3C0 ADCS R3, R1, R3,LSL#1
RAM:0201D3C4 SUBCC R3, R3, R1
RAM:0201D3C8 ADCS R0, R0, R0
RAM:0201D3CC ADCS R3, R1, R3,LSL#1
RAM:0201D3D0 SUBCC R3, R3, R1
RAM:0201D3D4 ADCS R0, R0, R0
RAM:0201D3D8 ADCS R3, R1, R3,LSL#1
RAM:0201D3DC SUBCC R3, R3, R1
RAM:0201D3E0 ADCS R0, R0, R0
RAM:0201D3E4 ADCS R3, R1, R3,LSL#1
RAM:0201D3E8 SUBCC R3, R3, R1
RAM:0201D3EC ADCS R0, R0, R0
RAM:0201D3F0 ADCS R3, R1, R3,LSL#1
RAM:0201D3F4 SUBCC R3, R3, R1
RAM:0201D3F8 ADCS R0, R0, R0
RAM:0201D3FC ADCS R3, R1, R3,LSL#1
RAM:0201D400 SUBCC R3, R3, R1
RAM:0201D404 ADCS R0, R0, R0
RAM:0201D408 ADCS R3, R1, R3,LSL#1
RAM:0201D40C SUBCC R3, R3, R1
RAM:0201D410 ADCS R0, R0, R0
RAM:0201D414 ADCS R3, R1, R3,LSL#1
RAM:0201D418 SUBCC R3, R3, R1
RAM:0201D41C ADCS R0, R0, R0
RAM:0201D420 ADCS R3, R1, R3,LSL#1
RAM:0201D424 SUBCC R3, R3, R1
RAM:0201D428 ADCS R0, R0, R0
RAM:0201D42C ADCS R3, R1, R3,LSL#1
RAM:0201D430 SUBCC R3, R3, R1
RAM:0201D434 ADCS R0, R0, R0
RAM:0201D438 ADCS R3, R1, R3,LSL#1
RAM:0201D43C SUBCC R3, R3, R1
RAM:0201D440 ADCS R0, R0, R0
RAM:0201D444 ADCS R3, R1, R3,LSL#1
RAM:0201D448 SUBCC R3, R3, R1
RAM:0201D44C ADCS R0, R0, R0
RAM:0201D450 ADCS R3, R1, R3,LSL#1
RAM:0201D454 SUBCC R3, R3, R1
RAM:0201D458 ADCS R0, R0, R0
RAM:0201D45C ADCS R3, R1, R3,LSL#1
RAM:0201D460 SUBCC R3, R3, R1
RAM:0201D464 ADCS R0, R0, R0
RAM:0201D468 ADCS R3, R1, R3,LSL#1
RAM:0201D46C SUBCC R3, R3, R1
RAM:0201D470 ADCS R0, R0, R0
RAM:0201D474 ADCS R3, R1, R3,LSL#1
RAM:0201D478 SUBCC R3, R3, R1
RAM:0201D47C ADCS R0, R0, R0
RAM:0201D480 ADCS R3, R1, R3,LSL#1
RAM:0201D484 SUBCC R3, R3, R1
RAM:0201D488 ADCS R0, R0, R0
RAM:0201D48C ADCS R3, R1, R3,LSL#1
RAM:0201D490 SUBCC R3, R3, R1
RAM:0201D494 ADCS R0, R0, R0
RAM:0201D498 ADCS R3, R1, R3,LSL#1
RAM:0201D49C SUBCC R3, R3, R1
RAM:0201D4A0 ADCS R0, R0, R0
RAM:0201D4A4 ADCS R3, R1, R3,LSL#1
RAM:0201D4A8 SUBCC R3, R3, R1
RAM:0201D4AC ADCS R0, R0, R0
RAM:0201D4B0 ADCS R3, R1, R3,LSL#1
RAM:0201D4B4 SUBCC R3, R3, R1
RAM:0201D4B8 ADCS R0, R0, R0
RAM:0201D4BC ADCS R3, R1, R3,LSL#1
RAM:0201D4C0 SUBCC R3, R3, R1
RAM:0201D4C4 ADCS R0, R0, R0
RAM:0201D4C8 ADCS R3, R1, R3,LSL#1
RAM:0201D4CC SUBCC R3, R3, R1
RAM:0201D4D0 ADCS R0, R0, R0
RAM:0201D4D4 ADCS R3, R1, R3,LSL#1
RAM:0201D4D8 SUBCC R3, R3, R1
RAM:0201D4DC ADCS R0, R0, R0
RAM:0201D4E0 ADCS R3, R1, R3,LSL#1
RAM:0201D4E4 SUBCC R3, R3, R1
RAM:0201D4E8 ADCS R0, R0, R0
RAM:0201D4EC MOV R1, R3
RAM:0201D4F0 BX LR
Eccolo qui, in tutta la sua gloria: quello che ho chiamato la "pazza routine per la lunghezza dei file." Quel 0x5398 non era infatti la sua lunghezza compressa, ma una lunghezza compressa con una codificazione che è stata decodificata da questa routine. Ecco un breve FAQ:
- D: Perché questa routine è così ripetitiva?
A: Questo è il risultato di una funzione di alcuni compilatori (tra cui i compilatori di ARM) chiamati loop unrolling. Praticamente, c'è una riduzione in favore del tempo di esecuzione rispetto allo spazio del programma quando il compilatore può determinare staticamente quanti loop ci saranno durante la compilazione. - D: Cosa significa?
A: Non preoccuparti, non è così importante. Diciamo che, quello è un loop, quindi possiamo trattarlo come un loop. - D: Vedo molte istruzioni
ADCSeSUBCC. A cosa servono?
A:ADCSsignifica "add with carry, set flags" ("aumenta con trasporto, imposta flag"). In sintesi, significa che somma due numeri e, se l'operazione precedente è risultata in un "trasporto", Aggiungiamo uno alla somma. Infine impostiamo o riazzeriamo il flag del trasporto in base al caso in cui quell'addizione è risultata in un trasporto o no . Un "trasporto" in questo caso si riferisce ad un "overflow senza segno" – quando un intero a 32-bit và oltre il suo valore massimo e ritorna al suo valore minimo.SUBCCis “sub if carry clear” ("sottrai se trasporto a zero"). Questo significa che sottraiamo due numeri se l'operazione non è risultata in un trasporto. - D: Perché gli sviluppatori lo avrebbero fatto così?
A: Vogliono particolarmente rompermi le palle.
Fuori dalla Foresta
Phew! Quella era molta assembly. Potremmo continuare a vedere ogni subroutine, ma abbiamo già completato il nostro obiettivo iniziale: abbiamo capito molto sul come gli archivi bin di Shade funzionano. Se torniamo nella nostra lista originale di quello che ci siamo aspettati di trovare in un archivio:
- Abbiamo trovato il numero di file (sono i primi quattro byte dell'archivio).
- Mentre non c'era una posizione ovvia dei nomi dei file, abbiamo trovato la mappatura tra l'indice di un file (che sembra essere il modo in cui è cercato), il suo offset, e la sua lunghezza compressa.
- I dati dei file è decisamente presente e distanziata per essere allineata ogni 0x800 byte.
Ottimo! Questi sono tanti progressi. Vediamo se possiamo scrivere qualcosa per analizzare l'archivio.
Scrivere Il Nostro Analizzatore
Iniziamo pensando a come vogliamo rappresentare i nostri file di archivio in C#. Ci sono quattro archivi diversi, ognuno con il loro tipo di file – per me, può solo significare che è il momento di una classe generica. Tanto per iniziare, faremo una classe generica per rappresentare i file negli archivi.
public partial class FileInArchive
{
public uint MagicInteger { get; set; }
public int Index { get; set; }
public int Offset { get; set; }
public List<byte> Data { get; set; }
public byte[] CompressedData { get; set; }
public bool Edited { get; set; } = false;
public FileInArchive()
{
}
}
Roba abbastanza basilare – abbiamo le proprietà dell'intero magico, l'indice, l'offset, e i dati compressi/decompressi. Abbiamo anche una proprietà Edited per indicare se abbiamo modificato il file oppure no. Infine, abbiamo un costruttore vuoto per ora – Lo faremo implementare dalle classi derivate.
Ora per fare un file d'archivio generico:
public class ArchiveFile<T>
where T : FileInArchive, new()
{
public const int FirstMagicIntegerOffset = 0x20;
public string FileName { get; set; } // e.g. evt.bin
public int NumFiles { get; set; }
public int MagicIntegerMsbMultiplier { get; set; }
public int MagicIntegerLsbMultiplier { get; set; }
public int MagicIntegerLsbAnd { get; set; }
public int MagicIntegerMsbShift { get; set; }
public List<uint> MagicIntegers { get; set; } = new();
public List<T> Files { get; set; } = new();
}
Tutta questa è roba che abbiamo visto prima. Ora, per il costruttore.
public ArchiveFile(byte[] archiveBytes)
{
NumFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
MagicIntegerMsbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x04).Take(4).ToArray());
MagicIntegerLsbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x08).Take(4).ToArray());
MagicIntegerLsbAnd = BitConverter.ToInt32(archiveBytes.Skip(0x10).Take(4).ToArray());
MagicIntegerMsbShift = BitConverter.ToInt32(archiveBytes.Skip(0x0C).Take(4).ToArray());
for (int i = FirstMagicIntegerOffset; i < (NumFiles * 4) + 0x20; i += 4)
{
MagicIntegers.Add(BitConverter.ToUInt32(archiveBytes.Skip(i).Take(4).ToArray()));
}
Qui, stiamo solo estraendo i valori trovati dall'header per poi fare un ciclo ed estrarre tutti gli interi magici.
Prima che arriviamo ad aggiungere i file nell'archivio, dobbiamo convertire quella funzione compressa. Potrei divulgarmi e spiegare come l'ho convertito dall'assembly passo dopo passo, ma sarebbe una spiegazione troppo lunga. Quindi, invece, ecco direttamente il codice:
public int GetFileLength(uint magicInteger)
{
// routine del tutto pazza
int magicLengthInt = 0x7FF + (int)((magicInteger & (uint)MagicIntegerLsbAnd) * (uint)MagicIntegerLsbMultiplier);
int standardLengthIncrement = 0x800;
if (magicLengthInt < standardLengthIncrement)
{
magicLengthInt = 0;
}
else
{
int magicLengthIntLeftShift = 0x1C;
uint salt = (uint)magicLengthInt >> 0x04;
if (standardLengthIncrement <= salt >> 0x0C)
{
magicLengthIntLeftShift -= 0x10;
salt >>= 0x10;
}
if (standardLengthIncrement <= salt >> 0x04)
{
magicLengthIntLeftShift -= 0x08;
salt >>= 0x08;
}
if (standardLengthIncrement <= salt)
{
magicLengthIntLeftShift -= 0x04;
salt >>= 0x04;
}
magicLengthInt = (int)((uint)magicLengthInt << magicLengthIntLeftShift);
standardLengthIncrement = 0 - standardLengthIncrement;
bool carryFlag = Helpers.AddWillCauseCarry(magicLengthInt, magicLengthInt);
magicLengthInt *= 2;
int pcIncrement = magicLengthIntLeftShift * 12;
for (; pcIncrement <= 0x174; pcIncrement += 0x0C)
{
// ADCS
bool nextCarryFlag = Helpers.AddWillCauseCarry(standardLengthIncrement, (int)(salt << 1) + (carryFlag ? 1 : 0));
salt = (uint)standardLengthIncrement + (salt << 1) + (uint)(carryFlag ? 1 : 0);
carryFlag = nextCarryFlag;
// SUBCC
if (!carryFlag)
{
salt -= (uint)standardLengthIncrement;
}
// ADCS
nextCarryFlag = Helpers.AddWillCauseCarry(magicLengthInt, magicLengthInt + (carryFlag ? 1 : 0));
magicLengthInt = (magicLengthInt * 2) + (carryFlag ? 1 : 0);
carryFlag = nextCarryFlag;
}
}
return magicLengthInt * 0x800;
}
Ora abbiamo una funzione che determina la lunghezza compressa di un file in base al suo intero magico. Ma c'è un problema – quando salviamo il file, dobbiamo invertirlo e andare dalla lunghezza compressa all'intero magico. Come lo facciamo?
Beh, ad un certo punto, qualcuno aveva un programma per farlo, ma non ero io. Inoltre, questa funzione è troppo per la mia testa e non ho idea neanche di come iniziare a costruirla. Ma non finisce qui per noi – ricordate che il valore 0x5398 ha solo 17-bit di lunghezza. Questo significa che i valori possibili dell'intero codificato (quindi l'input della pazza routine per la lunghezza del file) sono compresi tra 0 e 0x1FFFF. Questi sono solo 131,072 valori possibili, i quali non sono così tanti. Quindi dobbiamo... calcolare tutti i valori codificati possibili basandoci sulla lunghezza del file e aggiungerli in un dizionario. (Visto che questi valori sono costanti, lo facciamo solo una volta nel costruttore.)
for (int i = 0; i <= MagicIntegerLsbAnd; i++)
{
int length = GetFileLength((uint)i);
if (!LengthToMagicIntegerMap.ContainsKey(length))
{
LengthToMagicIntegerMap.Add(length, i);
}
}
Poi quando vogliamo un nuovo intero magico, facciamo semplicemente:
public uint GetNewMagicInteger(T file, int compressedLength)
{
uint offsetComponent = (uint)(file.Offset / MagicIntegerMsbMultiplier) << MagicIntegerMsbShift;
int newLength = (compressedLength + 0x7FF) & ~0x7FF; // arrotonda al 0x800 più vicino
int newLengthComponent = LengthToMagicIntegerMap[newLength];
return offsetComponent | (uint)newLengthComponent;
}
Infine, siamo pronti ad analizzare i file. Tutto quello che dobbiamo fare è un ciclo tra gli interi magici, trovare l'offset e la lunghezza compressa di ognuno di essi, e usarli per prendere i dati del file e analizzarli in un derivato FileInArchive.
for (int i = 0; i < MagicIntegers.Count; i++)
{
int offset = GetFileOffset(MagicIntegers[i]);
int compressedLength = GetFileLength(MagicIntegers[i]);
byte[] fileBytes = archiveBytes.Skip(offset).Take(compressedLength).ToArray();
if (fileBytes.Length > 0)
{
T file = new();
try
{
file = FileManager<T>.FromCompressedData(fileBytes, offset); // Non preoccuparti di questa funzione, tutto quello che fà è inizializzare il file.
}
catch (IndexOutOfRangeException)
{
Console.WriteLine($"Fallita l'analisi del file in 0x{i:X8} a causa dell'indice fuori dal range (molto probabilmente durante la decompressione)");
}
file.Offset = offset;
file.MagicInteger = MagicIntegers[i];
file.Index = i + 1;
file.Length = compressedLength;
file.CompressedData = fileBytes.ToArray();
Files.Add(file);
}
}
Quindi ora abbiamo un analizzatore funzionante. Possiamo scrivere velocemente una GUI (Graphics User Interface, l'interfaccia grafica) che ci dice com'è il caricamento del file e…
![Un'interfaccia GUI che mostra lo script estratto dal gioco[(/images/blog/0003/24_archive_interface.png)
Molto bello! (Il testo a destra è un'anteprima di quello che stiamo per fare – Stavo lavorando sull'analisi dei file degli eventi/script allo stesso tempo stavo lavorando nell'analizzare gli archivi, ma non parleremo del reverse-engineering degli eventi in questo post.) Quindi ora possiamo aprire evt.bin e anche modificarne i file al suo interno. C'è ancora un passaggio rimasto, però – Dobbiamo essere in grado di salvare gli archivi bin una volta che abbiamo finito di modificarli.
Salvare l'archivio
Il metodo ideale per salvare l'archivio è di ricostruirlo da capo, ma poiché ci sono dei dati nell'header che non capiamo a pieno, dobbiamo limitarci a modificare l'header che abbiamo. Quindi, iniziamo aggiungendo semplicemente l'intero header che abbiamo preso durante l'analisi.
public byte[] GetBytes()
{
List<byte> bytes = new();
bytes.AddRange(Header);
Poi, faremo un ciclo attraverso tutti i file e li aggiungeremo nell'archivio in ordine. Se il file non è stato modificato, allora lo aggiungeremo direttamente nell'archivio. Se il file è stato modificato, invece, dovremo comprimere i dati modificati.
for (int i = 0; i < Files.Count; i++)
{
byte[] compressedBytes;
if (!Files[i].Edited || Files[i].Data is null || Files[i].Data.Count == 0)
{
compressedBytes = Files[i].CompressedData;
}
else
{
compressedBytes = Helpers.CompressData(Files[i].GetBytes());
}
bytes.AddRange(compressedBytes);
Qui, abbiamo incontrato un ostacolo – in certi casi, il file modificato sarà più lungo del file originale, vero? Questo succederà più spesso di quel che pensiamo visto che la mia implementazione dell'algoritmo di compressione è molto meno efficace, quindi anche i file che sono della stessa dimensione quando sono decompressi, saranno più grandi dopo la ricompressione. La soluzione a questo problema è molto semplice, ma è un po' una seccatura: spostiamo tutto sotto.
Perché spostare sotto le cose è seccante? Beh, ha sempre a che fare con gli interi magici – essi contengono offset per ogni file. Spostando i file al di sotto, gli stiamo cambiando l'offset, il che significa che anche l'intero magico cambierà. Quindi dobbiamo scrivere del codice per farlo.
if (i < Files.Count - 1) // Se non siamo nell'ultimo file
{
int pointerShift = 0; // Assumendo che non cambieremo per niente gli offset
while (bytes.Count % 0x10 != 0) // si assicura che i file siano allineati a 16-bit
{
bytes.Add(0);
}
// Se le dimensioni dell'archivio costruito fin'ora sono più grandi
// dell'offset del prossimo file, allora dobbiamo aggiustare quest'ultimo
if (bytes.Count > Files[i + 1].Offset)
{
// Calcolare di quanto dobbiamo cambiare l'intero magico
pointerShift = ((bytes.Count - Files[i + 1].Offset) / MagicIntegerMsbMultiplier) + 1;
}
if (pointerShift > 0)
{
// Calcolare il nuovo intero magico in base a quanto deve essere cambiato
Files[i + 1].Offset = ((Files[i + 1].Offset / MagicIntegerMsbMultiplier) + pointerShift) * MagicIntegerMsbMultiplier;
int magicIntegerOffset = FirstMagicIntegerOffset + (i + 1) * 4;
uint newMagicInteger = GetNewMagicInteger(Files[i + 1], Files[i + 1].Length);
Files[i + 1].MagicInteger = newMagicInteger;
MagicIntegers[i + 1] = newMagicInteger;
bytes.RemoveRange(magicIntegerOffset, 4);
bytes.InsertRange(magicIntegerOffset, BitConverter.GetBytes(Files[i + 1].MagicInteger));
}
// Aggiunge spazio al file
while (bytes.Count < Files[i + 1].Offset)
{
bytes.Add(0);
}
}
Bum. Abbiamo il codice funzionante che sposterà gli interi magici. Quindi proviamolo– modifichiamo un file e salviamo l'archivio per vedere se possiamo cambiare del testo.

Ti presento il primo testo che ho modificato nel gioco. 🥰
Se sei interessato nel vedere il risultato finale del codice sull'archivio, puoi trovarlo su GitHub!
Prossimamente
Abbiamo analizzato e re-impacchettato l'archivio con successo. Il prossimo argomento di cui parleremo riguarda i primi file sul quale ho fatto reverse-engineering: i file degli eventi, che contenevano lo script del gioco. Ma prima di quello, pubblicherò un addendum in questi due post che conterranno le risposte a delle domande spesso chieste e qualche nota nel vero processo sul quale siamo passati per farlo funzionare. Grazie per la lettura!
Fuyuko è una traduttrice italiana e un'aspirante programmatrice a cui piace la tecnologia dei primi anni 2000.