Sfide nel ROM Hacking di Chokuretsu Parte 1 - Craccare un Algoritmo di Compressione!
Benvenuti! Questo è il primo di una serie di post del blog che andrà nel dettaglio riguardo le sfide tecniche che coinvolgono la traduzione di Suzumiya Haruhi no Chokuretsu (La Serie Di Haruhi Suzumiya). Questi blog tendono ad essere al quanto dettagliati e includeranno cose come stringhe di codice, ma scritte in modo di essere capili da un pubblico generale. Se hai delle domande o dei commenti, puoi sempre mandarci un tweet!
Tutto questo progetto iniziò con due post sul forum di GBATemp da un utente chiamato Cerber (che ora è uno dei nostri grafici!) che stava chiedendo aiuto a tradurre un oscuro gioco per DS basato sulla serie di Haruhi. Aveva fatto molti progressi nel trovare lo script e rimpiazzarlo con dei caratteri inglesi, ma non riusciva ad inserire il testo per intero.
Quello che Cerber stava facendo esattamente era aprire la ROM in un editor esadecimale (un programma che permette di modificare direttamente i file in binario) e cercare il testo che vedeva nel gioco. Lui riuscì a trovare lo script, ma fu messo in difficoltà da quello che chiamò "codice di gioco" che stava attorno al testo che provò a cambiare -- modificare le sezioni che lui mise in rosso avrebbe rotto completamente il gioco.

Ecco una spiegazione veloce di quello che vediamo: a sinistra, abbiamo il binario nel file, rappresentato da una serie di byte in esadecimale. L'esadecimale è anche chiamato base 16 -- mentre noi utilizziamo solitamente il decimale (base 10 -- 0, 1, 2, 3, 4, 5, 6, 7, 8 e 9) e i computer utilizzano il binario (base 2 -- 0 e 1), i programmatori spesso fanno uso dell'esadecimale perché ci permette di rappresentare ogni singolo byte in due caratteri. Quando scriviamo un numero, per distinguere la base utilizziamo spesso 0x come prefisso per l'esadecimale (0x17 è 23 in decimale) e 0b per rappresentare numeri in binario (0b0000_0100 è 4 in decimale).
I caratteri sulla destra rappresentano i byte che vediamo a sinistra interpretati attraverso un encoding. Potresti aver sentito parlare dell'ASCII, l'encoding più basilare -- ogni lettera dell'alfabeto è rappresentata da un singolo byte. Questo gioco utilizza un encoding chiamato Shift-JIS, che è come il giapponese veniva rappresentato prima dell'Unicode.
Pensando alle mie esperienze in passato, feci qualche investigazione per poi postare una risposta probabilmente da squilibrato:
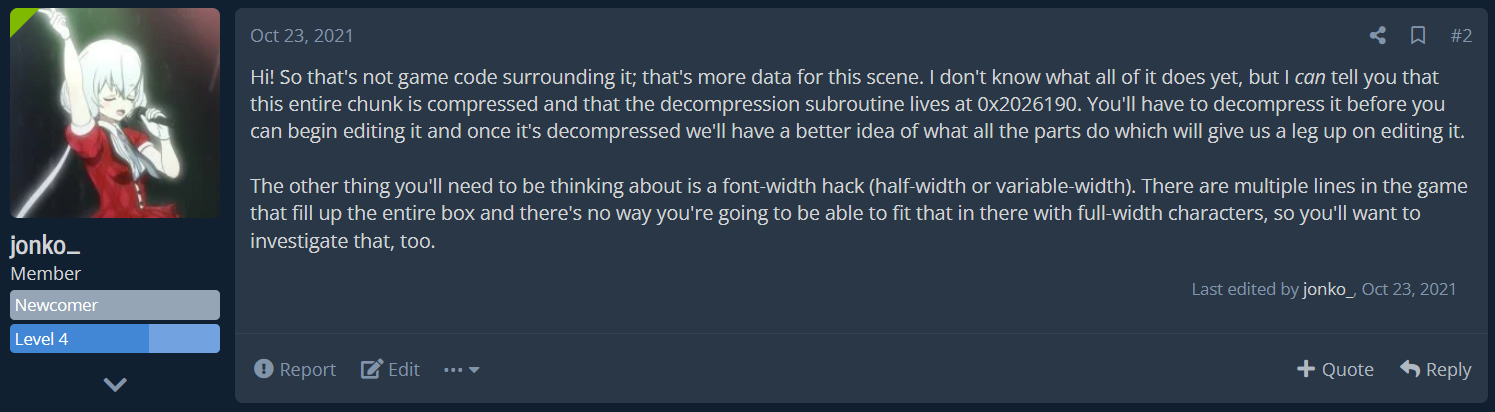
Ciao! Allora, quello non è codice del gioco; sono dati per questa scena. Non so ancora cosa fa tutto questo, ma posso dirti che tutto questo pezzo è compresso e che la subroutine di decompressione è in 0x2026190. Dovrai decomprimerlo prima di poterlo modificare e una volta che è decompresso sarà più facile farsi un'idea di cosa fa ogni parte dandoci un aiuto nel modificarle.
Un altra cosa a cui dovrai pensare è una modifica per la larghezza del font (di lunghezza media o variabile). Ci sono alcune linee nel gioco che riempiono tutto il box del testo, e sarebbe impossibile farci stare la traduzione per intero con dei caratteri a piena larghezza, quindi dovrai investigare pure su quello.
Quindi facciamolo passo dopo passo.
Compressione
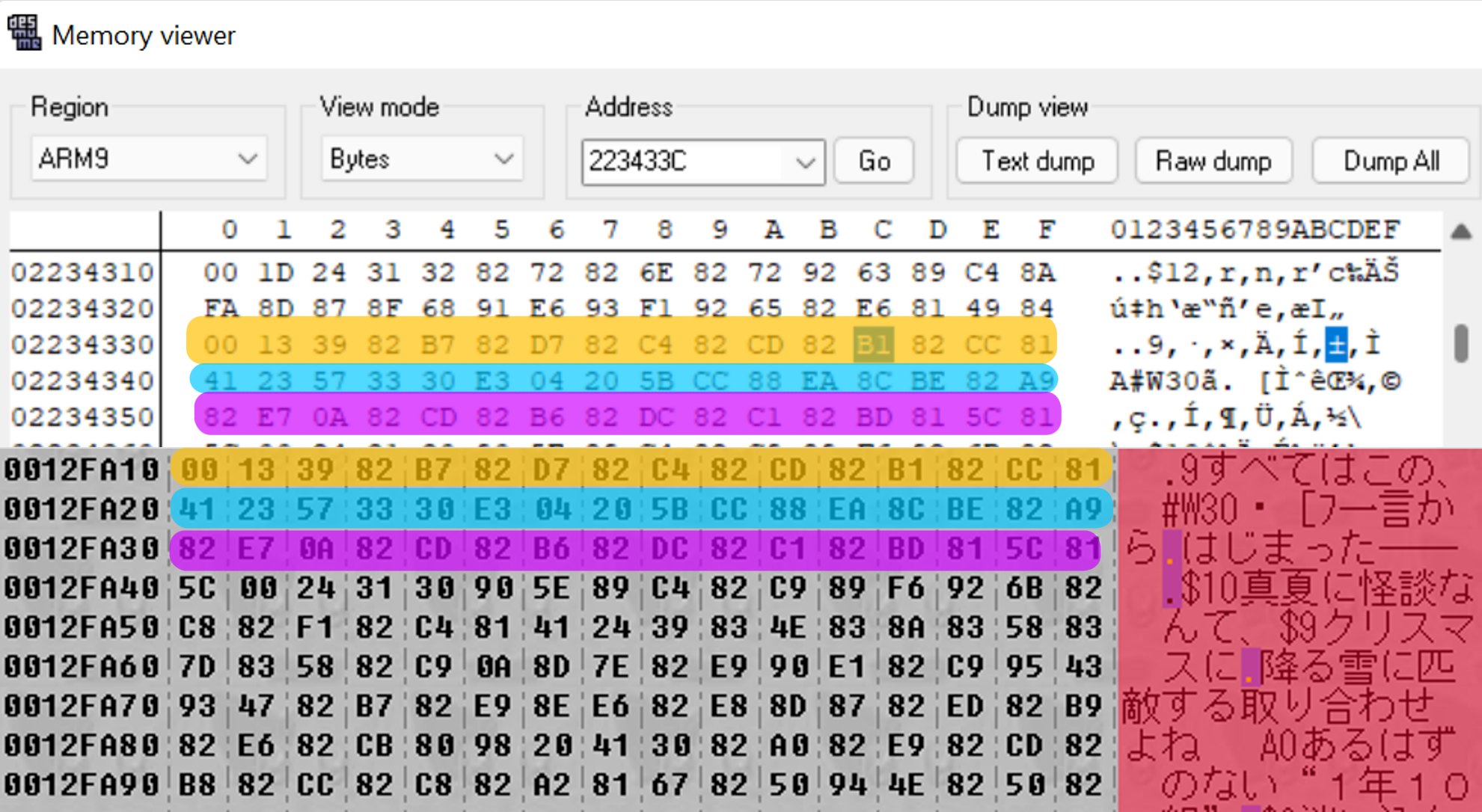
Come facevo a sapere che questa scena era compressa? Beh, guardando al suo screenshot, possiamo vedere chiaramente come il testo di gioco viene mostrato nell'editor esadecimale (ho evidenziato un esempio in giallo), ma alcune porzioni di testo mancano -- Per esempio, la parte con "ハルヒの" che ho evidenziato sotto è rimpiazzata da una sequenza di caratteri più corta che ho evidenziato in blu.

Questo è un segno di quello che chiamiamo run-length encoding -- un metodo per comprimere file che si focalizza ad eliminare ripetizioni. Va bene, ora sappiamo che è compresso, e ora cosa facciamo? Sappiamo in nostro obiettivo: vogliamo rimpiazzare il testo nel file con del testo inglese. Per farlo, dovremo decomprimere il testo noi stessi in modo da modificare il file. Tuttavia, poiché il gioco si aspetta di avere il testo compresso, dovremo anche ricomprimere il file in modo da reinserirlo nel gioco. Bene, iniziamo.
Trovare la Subroutine di Decompressione
Ora abbiamo moltissime informazioni a nostra disposizione qui. Abbiamo un file del quale sappiamo già che è compresso, abbiamo una buona idea di come diventa una volta decompresso, e sappiamo dove il gioco utilizza quel file. Quindi, carichiamo il gioco in DeSmuME (l'emulatore che, al momento della scrittura, ha la migliore ricerca di memoria) e cercare un po' del testo che appare nel gioco.
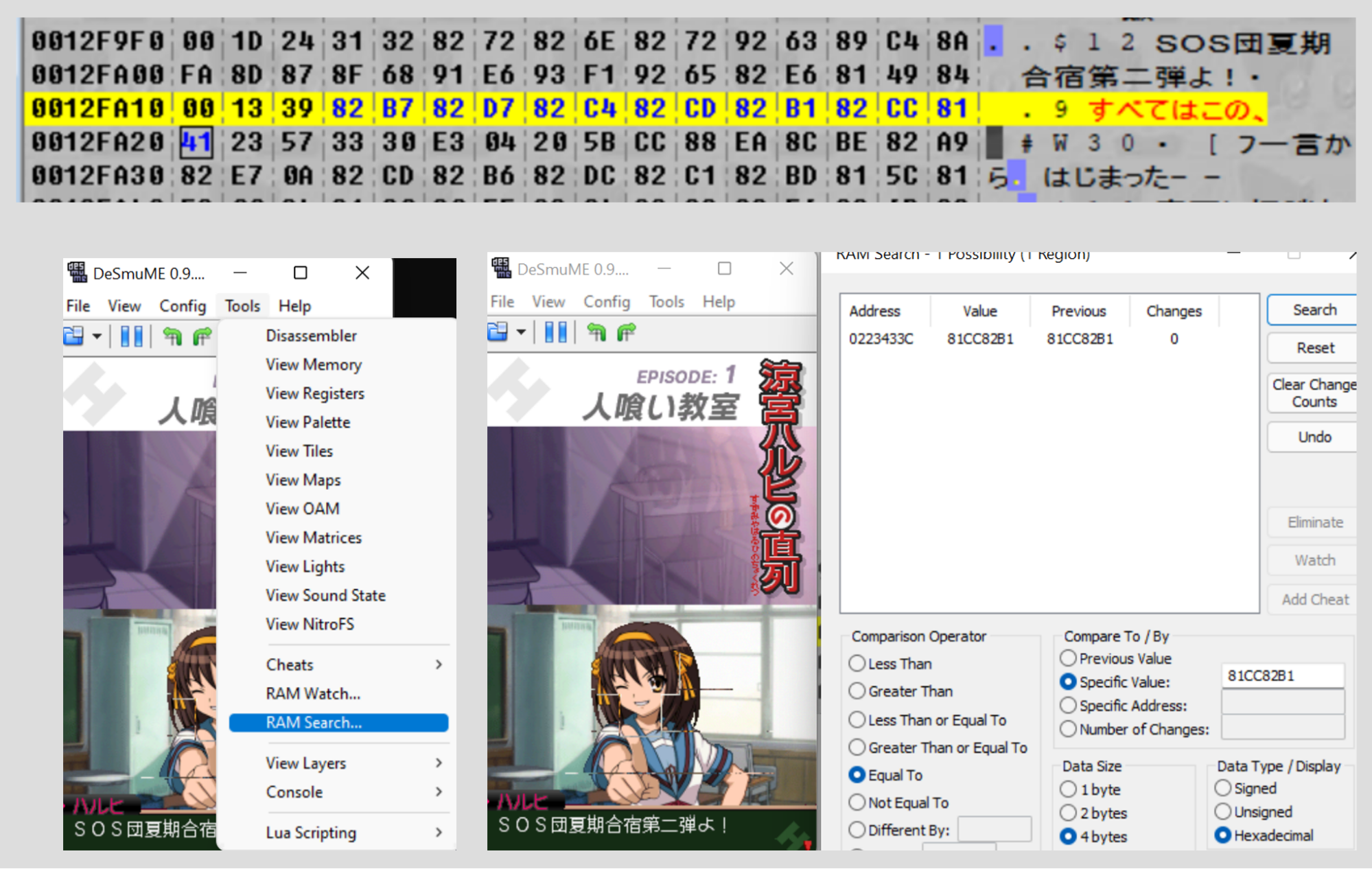
Qui stiamo cercando 0x81CC82B1 (la ricerca nella RAM di DeSmuME esprime i byte in ordine inverso) che corrisponde alla porzione del “この、” nel testo. Troviamo esattamente un risultato nell'indirizzo 0x0223433C -- fantastico. Andiamo in quell'indirizzo di memoria…
E coincide esattamente! Abbiamo trovato dove il file compresso viene caricato nella memoria. Quindi adesso, è ora di aprire il peggior emulatore per DS, ma anche l'unico con un debugger funzionante, no$GBA.
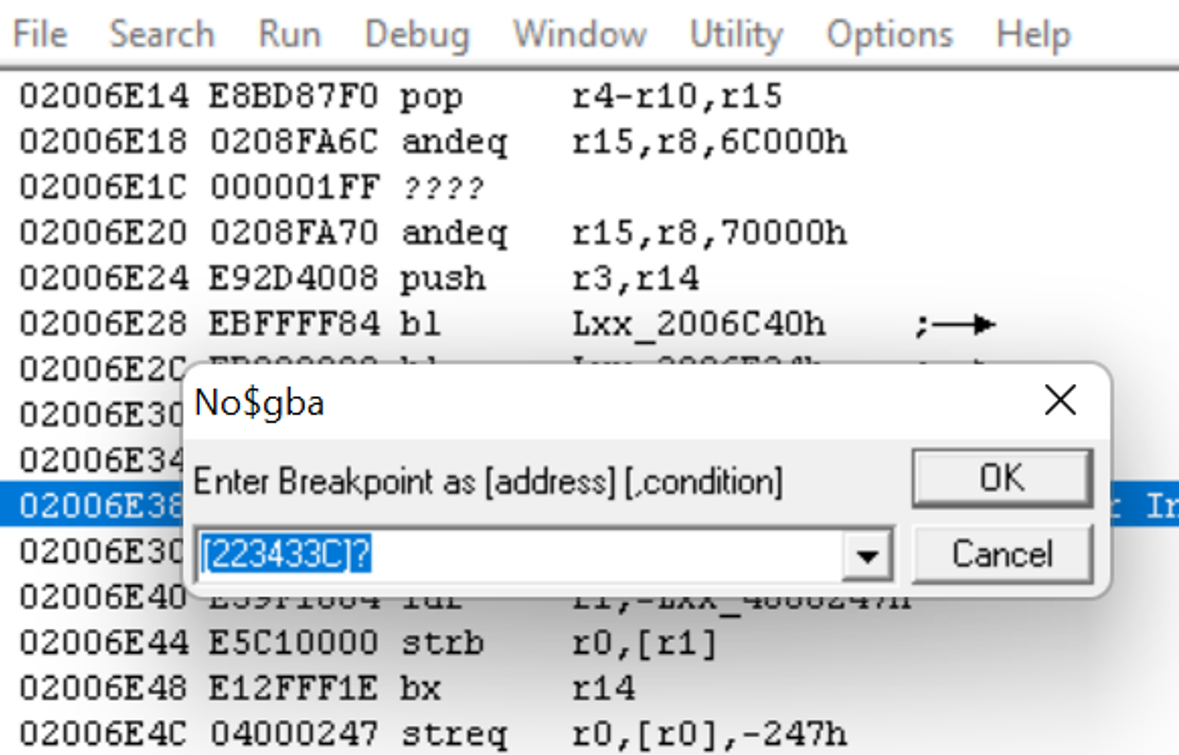
Andremo ad impostare un breakpoint di lettura per 0x0223433C. Come dissi prima, il motivo per il quale stiamo usando no$ è perché è l'unico che ha un debugger, e una delle funzioni dei debugger è la possibilità di aggiungere dei breakpoint. Un debugger ci permette di vedere quale codice è in esecuzione mentre il gioco gira, ed un breakpoint dice al debugger di fermarsi ad una certa linea di esecuzione. In questo caso questo breakpoint di lettura dice al debugger di fermare l'esecuzione appena legge l'indirizzo 0x0223433C. Il motivo per il quale dobbiamo fare questo, è perché la memoria fa accesso ad un file compresso quando viene decompresso, quindi ci aiuterà a trovare la subroutine di decompressione.
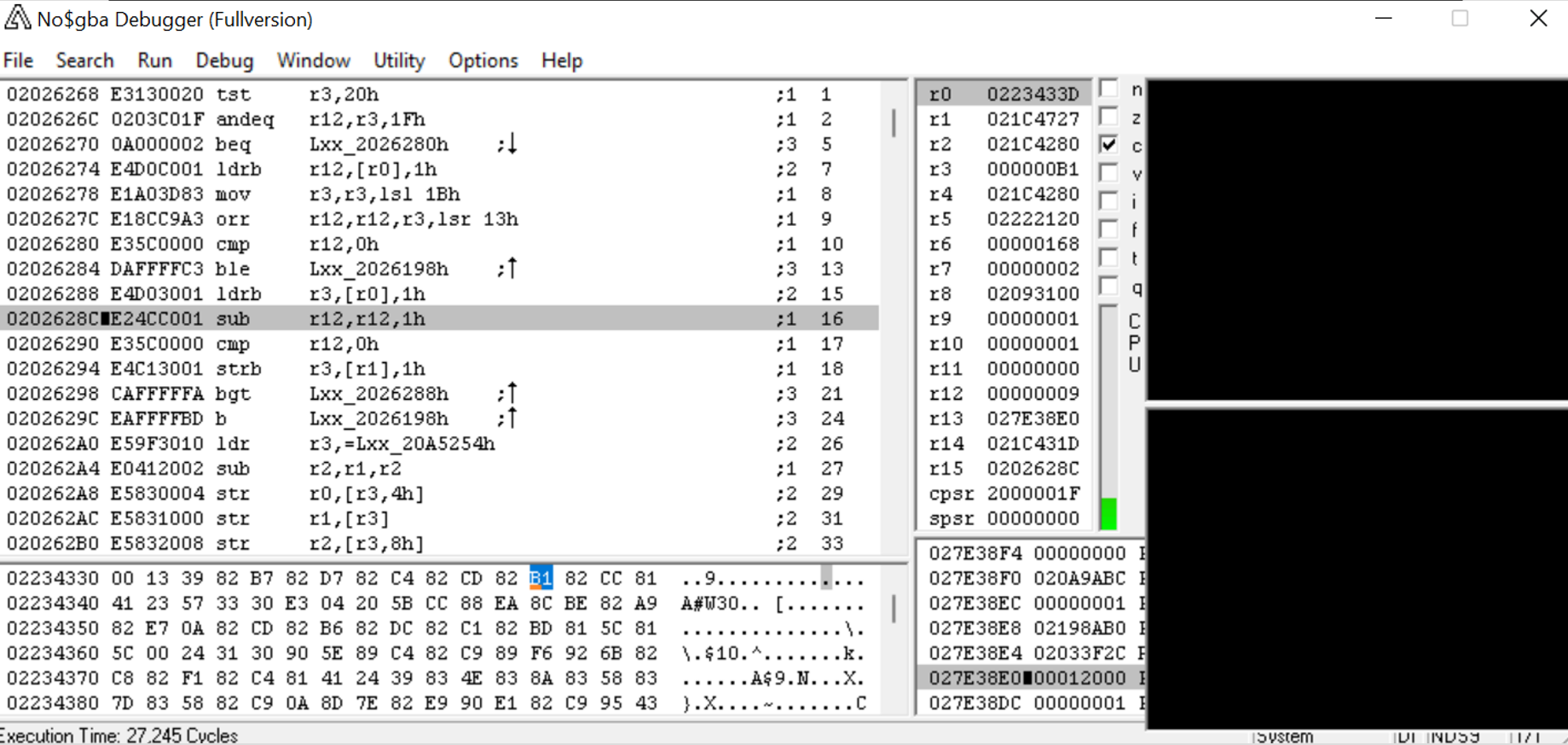
Voilà, abbiamo raggiunto il nostro breakpoint. Il gioco legge da 0x223433C all'istruzione in 0x2026288. Ora dobbiamo aprire il nostro terzo programma, IDA (l'Interactive Disassembler). (È meglio notare che mentre io uso IDA, potete fare la stessa cosa usando Ghidra, un altro disassemblatore tipicamente usato che è pure gratis.)
Quindi in IDA, utilizziamo il plugin del caricatore di NDS per disassemblare la ROM di Chokuretsu in modo da vedere il codice assembly (spesso riferito come "disassembly") più facilmente. IDA fa qualcosa di abbastanza utile, ossia dividere il codice in subroutine (dette anche "funzioni"), che rende più facile vedere dove il codice inizia e finisce.

Quindi andiamo nell'indirizzo che abbiamo trovato…
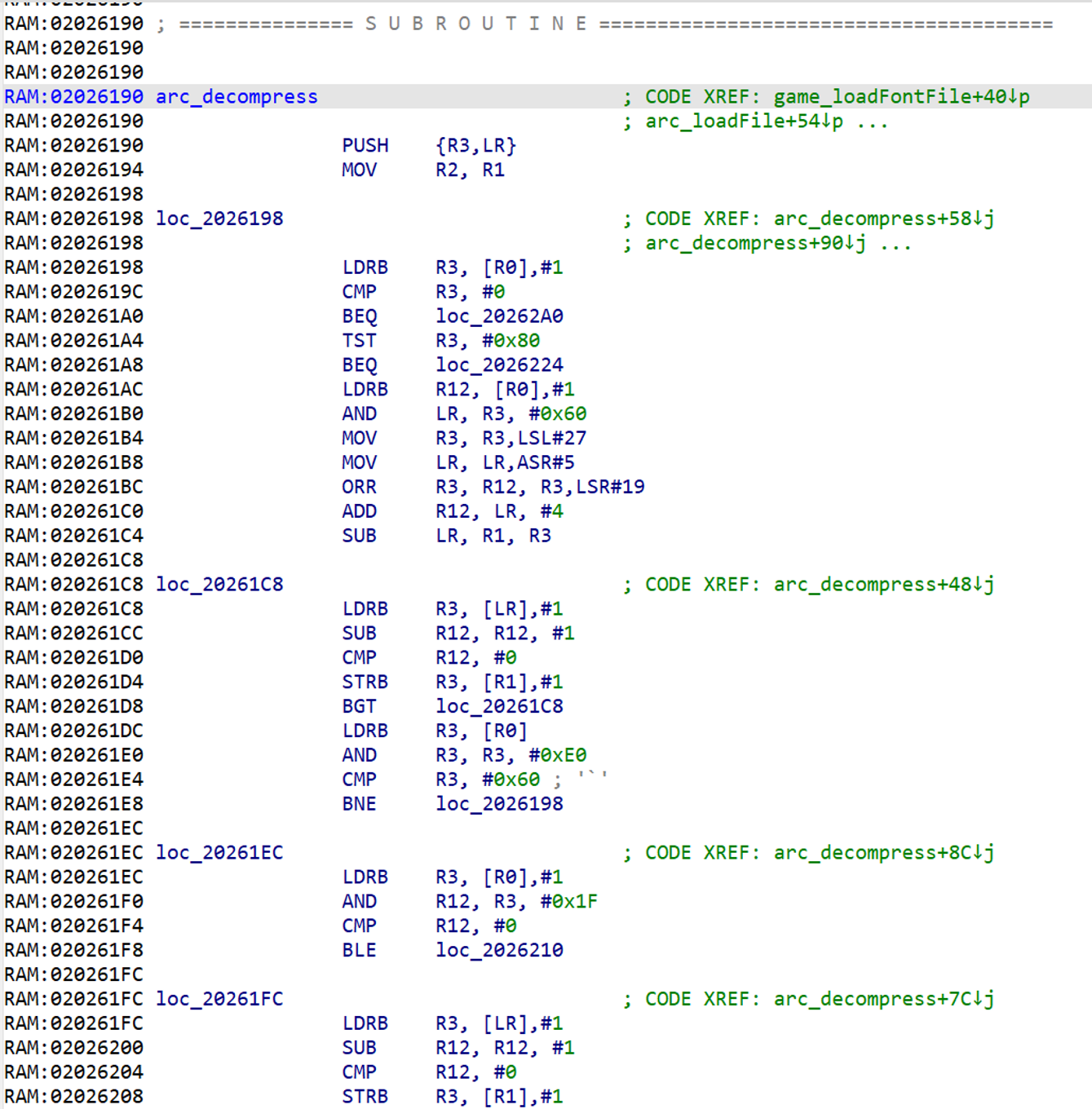
E l'abbiamo trovato! Quando un programma viene compilato, tutti i nomi delle cose come le funzioni e le variabili vengono tolti, quindi IDA rinominerà le subroutine in qualcosa come sub_2026190 di default -- tuttavia, lo andremo a cambiare in arc_decompress (che abbiamo già fatto nello screenshot) in modo che è più facile da trovare e richiamare. (arc sta per archivio -- ma ne parleremo nel prossimo post di questa serie.)
Questo è quello che intendevo quando dissi che la subroutine di decompressione si trova in 0x2026190 -- Scorrendo in sù scopriremo che la subroutine inizia in quel punto. Questo fu quanto riuscì a scoprire quando risposi al post di Cerber, ma è anche dove il divertimento inizia veramente -- è ora di decompilare l'algoritmo di decompressione.
Algoritmo di Reverse-Engineering
La prima cosa che ho fatto è stato creare una specie di "simulatore di assembly" -- Ho riscritto ogni stringa di codice dell'assembly in un programma C#. (La scelta di usare C# l'ho fatta solo perché è un linguaggio di alto livello con il quale mi trovo meglio io; si può usare anche Python, C++, JavaScript o qualsiasi linguaggio.) Perché farlo? Ai tempi ero ancora un principiante con assembly, quindi questo esercizio mi è servito per due motivi: primo, mi aiutò a conoscere meglio il disassembly; secondo, mi ha dato un programma che potevo eseguire sapendo per bene che sarebbe stato uguale a quello in assembly.
Il simulatore finì per essere così:
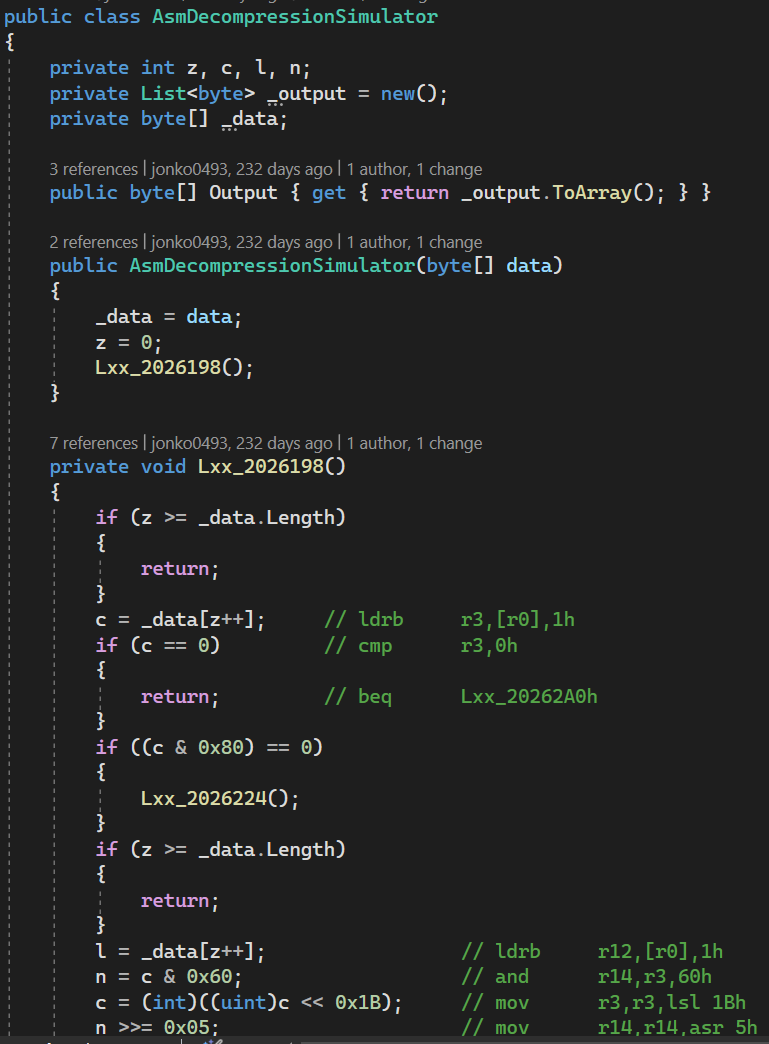
Per facilitare i riferimenti, ho annotato le stringhe di codice con dei commenti che mostrano quello che fa ogni istruzione nel disassembly alla quale corrispondono. Una volta completato, sono stato in grado di decomprimere i file in modo nativo! Tuttavia, è abbastanza inefficiente. Quindi proveremo invece a capire questo assembly in modo da renderlo del codice leggibile da un essere umano.
Un'Introduzione all'Assembly
Per farlo, dobbiamo prima capire cos'è l'assembly: assembly è un linguaggio a livello macchina, il che significa che è quello che il processore legge per eseguire le istruzioni. Quell'ultima parola è importante -- L'unità più basilare dell'assembly è un'istruzione. Ad esempio cose come ADD (somma due numeri) o SUB (sottrare due numeri).
Per operare sui valori in assembly, devono prima essere caricati in un registro. I registi possono essere visti come "le variabili della CPU" e sono numerati come R0, R1, R2, ecc. Il DS ne ha 15. I valori sono caricati nei registri dalla memoria (detta anche RAM), che ha uno spazio largo di binari accessibili che possono essere richiamati dalla CPU velocemente.
Il codice in assembly varia di piattaforma in piattaforma -- più nello specifico, varia in base all'architettura (che può essere vista come la famiglia o il tipo) del microchip. Il DS utilizza l'ARM assembly per il suo eseguibile principale, che è abbastanza comune e ben documentato. Il modo in cui io imparai ARM assembly fu provare a fare il debug dei codici per il Nintendo DS mentre cercavo su un'altra finestra quello che ogni istruzione faceva. Se vuoi dei buoni punti di riferimento per ARM, la documentazione officiale è molto istruttiva, tuttavia trovo che cercare su Google "ARM [istruzione che voglio capire meglio]" funziona a meraviglia.
Nel Dettaglio
L'Inizio
Partiamo dall'inizio:
RAM:02026198 LDRB R3, [R0],#1
RAM:0202619C CMP R3, #0
RAM:020261A0 BEQ loc_20262A0
RAM:020261A4 TST R3, #0x80
RAM:020261A8 BEQ loc_2026224
Vediamo cosa fa ognuna di queste istruzioni:
LDRB R3, [R0], #1– Questo carica il byte nell'indirizzo contenuto in R0 (che contiene la posizione attuale nel file) nel registro R3 e poi incrementa R0 di uno (Il che significa che ci spostiamo alla posizione del prossimo byte nel file). Visto che siamo all'inizio del file, questo ne carica il primo byte.CMP R3, #0;BEQ loc_20262A0–BEQsignifica "ramifica se è uguale," ma in realtà significa “ramifica se l'ultimo confronto è pari a zero.” Quindi, significa che se il valore che abbiamo appena caricato è 0, andremo a ramificare fino alla fine della subroutine. Possiamo ignorarlo per ora.TST R3, #0x80–TSTesegue un bitwise-and . Un bitwise-and confronta due byte e dà un risultato dove ogni bit risulta 1 solo se quel bit è uno in entrambi i bit che confronta. Nel caso dove R3 è 0xAA, ci verrebbe dato un risultato del genere:
10101010 (0xAA)
10000000 (0x80)
_______
10000000 (0x80)
Quindi questo TST seguito dal BEQ sta solo controllando se il primo bit è pari a zero o no. Se è a zero, lo ramifichiamo a 0x2026224. Ramifichiamolo lì adesso (So delle cose che voi non sapete quindi so già che questa ramificazione sarà più semplice lol). Ma prima, lo convertiremo in C#:
int blockByte = compressedData[z++];
if (blockByte == 0)
{
break;
}
if ((blockByte & 0x80) == 0)
{
// Fai qualcosa
}
else
{
// Fai qualcos'altro
}
Fin'ora è abbastanza semplice – stiamo solo controllando se il primo byte è zero.
Scrittura Diretta
RAM:02026224 TST R3, #0x40
RAM:02026228 BEQ loc_2026268
TST R3, #0x40–Adesso sta controllando se il secondo bit è impostato. Se lo è, salteremo a 0x2026268. Torneremo in questa sezione in un secondo, ma prima saltiamo lì dopo che convertiamo anche questo pezzo in C#:
if ((blockByte & 0x80) == 0)
{
if ((blockByte & 0x40) == 0)
{
// Fai qualcosa 0x80
}
else
{
// Fai qualcos'altro 0x80
}
}
else
{
// Fai qualcos'altro
}
RAM:02026268 loc_2026268 ; CODE XREF: arc_decompress+98↑j
RAM:02026268 TST R3, #0x20
RAM:0202626C ANDEQ R12, R3, #0x1F
RAM:02026270 BEQ loc_2026280
RAM:02026274 LDRB R12, [R0],#1
RAM:02026278 MOV R3, R3,LSL#27
RAM:0202627C ORR R12, R12, R3,LSR#19
RAM:02026280
RAM:02026280 loc_2026280 ; CODE XREF: arc_decompress+E0↑j
RAM:02026280 CMP R12, #0
RAM:02026284 BLE loc_2026198
RAM:02026288
RAM:02026288 loc_2026288 ; CODE XREF: arc_decompress+108↓j
RAM:02026288 LDRB R3, [R0],#1
RAM:0202628C SUB R12, R12, #1
RAM:02026290 CMP R12, #0
RAM:02026294 STRB R3, [R1],#1
RAM:02026298 BGT loc_2026288
RAM:0202629C B loc_2026198
Questo è un gran bel pezzo di codice, ma non preoccuparti. Ce la possiamo fare.
TST R3, #0x20;ANDEQ R12, R3, #0x1F– Ora stiamo provando il terzo bit del nostro primo byte. Se è zero, prenderemo i suoi ultimi cinque bit (0x1F = 0xb0001_1111) e li ramificheremo a 0x2026280. Ci arriveremo in un secondo.LDRB R12, [R0], #1– Stiamo caricando il prossimo byte dal file in un registro (R12). Quindi se il terzo bit di quel primo byte è stato impostato, significa che dovremo fare qualcosa con il prossimo byte.MOV R3, R3, LSL#27;ORR R12, R12, R3, LSR#19–LSLè “logical shift left” (spostamento logico a sinistra) andLSRis “logical shift right” (spostamento logico a destra), nel senso che sposterà i bit in R3 a sinistra o a destra di 27 e 19. Spostarli a sinistra di 27 e a destra di 19 significa effettivamente che li sposterà a sinistra di 8 dopo aver riazzerato i 3 bit al di sopra, il che equivale a moltiplicareR3 & 0x1Fper 0x100. Con un bitwise-or, combiniamo il primo byte ed il secondo byte e leggiamo in un intero a 16-bit.
Questo sta calcolando qualcosa in una dichiarazione if (se) – lo possiamo rappresentare in C# così:
int value;
if ((blockByte & 0x20) == 0)
{
value = blockByte; // `& 0x1F` non è necessario visto che abbiamo già determinato che i bit 1-3 valgono 0
}
else
{
// bit 3 == 1 --> ha bisogno di due byte per indicare quanti dati deve leggere
value = compressedData[z++] + ((blockByte & 0x1F) * 0x100);
}
Non sappiamo ancora cosa fa questo valore, ma diventerà chiaro una volta che guardiamo la prossima sezione.
CMP R12, #0;BLE loc_2026198– Se il valore calcolato è 0, Torniamo immediatamente all'inizio della funzione.LDRB R3, [R0], #1– Come avrai ora capito, andremo a caricare il byte in R3.SUB R12, R12, #1– Sottraiamo 1 dal valore che abbiamo calcolato prima.CMP R12, #0– Confrontiamo il valore calcolato prima a 0.STRB R3, [R1], #1– Mettiamo il valore più recente che abbiamo appena letto nel buffer di dati decompresso e ci spostiamo di uno nel buffer.BGT loc_2026288– Se due passaggi prima R12 era maggiore di 0, andiamo al primo passaggio di questa sezione. Aha - è un loop!B loc_2026198– Se è minore o pari a 0, torniamo all'inizio della subroutine.
Questo in realtà è super semplice ora che sappiamo che questo è un loop. Il valore che stavamo calcolando prima è il numero di byte (numBytes) per copiare direttamente dal buffer input al buffer output. Quindi possiamo rappresentare questa sezione come:
for (int i = 0; i < numBytes; i++)
{
decompressedData.Add(compressedData[z++]);
}
Inoltre, il fatto che torniamo all'inizio della funzione ogni volta implica che è un loop.
Il programma che abbiamo scritto fin'ora è così:
for (int z = 0; z < compressedData.Length;)
{
int blockByte = compressedData[z++];
if (blockByte == 0)
{
break;
}
if ((blockByte & 0x80) == 0)
{
if ((blockByte & 0x40) == 0)
{
// bits 1 & 2 == 0 --> lettura diretta dei dati
int numBytes;
if ((blockByte & 0x20) == 0)
{
numBytes = blockByte; // `& 0x1F` non è necessario visto che abbiamo determinato che i bit 1-3 valgono 0
}
else
{
// bit 3 == 1 --> ha bisogno di due byte per indicare quanti dati leggere
numBytes = compressedData[z++] + ((blockByte & 0x1F) * 0x100);
}
for (int i = 0; i < numBytes; i++)
{
decompressedData.Add(compressedData[z++]);
}
}
Decomprimere un File
Essenzialmente, un algoritmo di compressione opera in questo modo: Un "byte di controllo" viene letto e i primi tre o quattro bit determinano le funzioni seguenti. Le opzioni di decompressione sono:
- Leggere un certo numero di dati direttamente nel buffer di decompressione
- Leggere un singolo byte e ripeterlo un certo numero di volte
- Fare un riferimento ad una posizione particolare nei dati decompressi e copiare in avanti quei byte
L'intera implementazione della decompressione può essere trovata qui.
E se proviamo a decomprimere un file…

Ecco lo script decompresso! Fantastico.
Creare la Routine di Compressione
Ora che capiamo come funziona l'algoritmo di decompressione per bene possiamo decomprimere tutti i file per sostituire il testo Giapponese in Inglese. Ma se vogliamo reinserirli nel gioco, dobbiamo essere in grado di ricomprimere i file modificati. Quindi dobbiamo implementare una routine di compresione. Non ci sarà una copia in assembly della routine come per la decompressione visto che non è presente nel gioco (i file sono stati compressi alla creazione del gioco, vengono solo decompressi nel gioco). Ma non è un problema - ora che sappiamo come funziona la decompressione, dobbiamo solo invertire il processo per comprimere i file.
Per esempio, possiamo implementare una modalità di "scrittura diretta" molto facilmente:
private static void WriteDirectBytes(byte[] writeFrom, List<byte> writeTo, int position, int numBytesToWrite)
{
if (numBytesToWrite < 0x20)
{
writeTo.Add((byte)numBytesToWrite);
}
else
{
int msb = 0x1F00 & numBytesToWrite;
byte firstByte = (byte)(0x20 | (msb / 0x100));
byte secondByte = (byte)(numBytesToWrite - msb);
writeTo.AddRange(new byte[] { firstByte, secondByte });
}
writeTo.AddRange(writeFrom.Skip(position - numBytesToWrite).Take(numBytesToWrite));
}
Prima, prendiamo il numero di byte che andremo a scrivere. Se quel numero è minore di 0x20 (in altre parole può essere contenuto nei cinque bit più bassi del byte di controllo), allora possiamo scrivere quel numero nel buffer dell'output. Altrimenti, dovremo calcolare i due byte da scrivere per rappresentare un numero più grande. Alla fine, scriviamo semplicemente i byte nel buffer dell'output.
Possiamo implementare una funzione simile (ahimè più complessa) per ripetere e riguardare le modalità. Il risultato finale può essere trovato qui.
La Prossima Volta
Ora abbiamo implementato sia la compressione che la decompressione, ma non abbiamo ancora finito. La prossima volta, dobbiamo avere a che fare con il fatto che questo file è solo uno dei tanti in un archivio, e dobbiamo capire come sostituirlo. Unitevi a noi nel prossimo post dove ci indulgeremo nel dettaglio.