Chokuretsu ROM Hacking Challenges Part 3 – Compression & Archive Follow-Up
My initial draft of the blog post covering the Shade bin archive files in Chokuretsu was long. Like, really long. There was a lot of stuff I necessarily had to cut in the final version in order to convey how I reverse-engineered the structure of the archive and got file reinsertion working. What’s more, a number of common questions came up in response to the first two posts and I hope to use this post to catalog my answers to some of them.
No One Knows What They’re Doing
When I started writing the archive code, I did so simply wanting to extract files and not understanding the actual structure of the bin archives at all. Thus, I wrote code that simply looked for spacing between files to identify their offsets. Even as I learned more about the archive structure, reverse-engineered the magic integers, and worked on file replacement and eventually file insertion, I kept this very flawed architecture. Impressively, this code actually stuck around until I wrote the previous blog post (lol). It caused a number of bugs – notably, I managed to corrupt a file in the graphics archive because it didn’t have spacing between it and its previous file (i.e. the previous file ended at something like 0x7F8 and it started at 0x800).
I feel like the previous blog post might have given the impression that things went perfectly from the start and I want to emphasize that they super did not. This is a process of trial and error and constant learning for me – I didn’t even put together that these were archives while I was in the process of reverse-engineering them and was instead calling them “custom filesystems.”
It wasn’t until Ermii politely asked if they were archives that I realized that…yeah, that’s exactly what they were.
The File Length
Something I left out of the archive post was the fact that I didn’t reverse-engineer the whole archive at once. The code was written ad-hoc as I figured out particular things here and there. I figured out the offsets before I even realized that the rest of the magic integers encoded for length, so I was replacing files in the archives without changing their lengths accordingly. This resulted in beautiful things like this:

Trying to replace the graphics files led to corruption because my compression routine was less efficient than the one the devs used, which meant that the compressed files I was reinserting into the game were longer than expected. I spent a lot of time trying to figure out what was going on before I finally determined the file length encoding.

Much better!
Writing Tests
So there was a lot of trial and error, which meant that I needed to be able to verify that things like the compression routine or archive reinsertion programs were working in a consistent way. A fantastic way to go about this is writing tests and that’s exactly what I did. See a test for the compression implementation I wrote below:
[Test]
[TestCase("evt_000", TestVariables.EVT_000_DECOMPRESSED, TestVariables.EVT_000_COMPRESSED)]
[TestCase("evt_66", TestVariables.EVT_66_DECOMPRESSED, TestVariables.EVT_66_COMPRESSED)]
[TestCase("evt_memorycard", TestVariables.EVT_MEMORYCARD_DECOMPRESSED, TestVariables.EVT_MEMORYCARD_COMPRESSED, false)]
[TestCase("grp_c1a", TestVariables.GRP_C1A_DECOMPRESSED, TestVariables.GRP_C1A_COMPRESSED, false)]
[TestCase("evt_test", TestVariables.EVT_TEST_DECOMPRESSED, TestVariables.GRP_TEST_COMPRESSED)]
[TestCase("grp_test", TestVariables.GRP_TEST_DECOMPRESSED, TestVariables.GRP_TEST_COMPRESSED)]
public void CompressionMethodTest(string filePrefix, string decompressedFile, string originalCompressedFile)
{
byte[] decompressedDataOnDisk = File.ReadAllBytes(decompressedFile);
byte[] compressedData = Helpers.CompressData(decompressedDataOnDisk);
File.WriteAllBytes($".\\inputs\\{filePrefix}_prog_comp.bin", compressedData);
if (!string.IsNullOrEmpty(originalCompressedFile))
{
Console.WriteLine($"Original compression ratio: {(double)File.ReadAllBytes(originalCompressedFile).Length / decompressedDataOnDisk.Length * 100}%");
}
Console.WriteLine($"Our compression ratio: {(double)compressedData.Length / decompressedDataOnDisk.Length * 100}%");
byte[] decompressedDataInMemory = Helpers.DecompressData(compressedData);
File.WriteAllBytes($".\\inputs\\{filePrefix}_prog_decomp.bin", decompressedDataInMemory);
Assert.AreEqual(StripZeroes(decompressedDataOnDisk), StripZeroes(decompressedDataInMemory), message: "Failed in implementation.");
}
This test compresses some data and then decompresses it to validate that the decompressed file is identical to the original one. This was used repeatedly while debugging the compression routine to ensure it was working as I implemented each part of it. Speaking of which…
The Compression Routine
I had a number of questions about how I actually implemented the compression routine, so I thought I’d delve into that a bit here.
I think the core process is actually pretty easy to understand: essentially, we’re just reversing what the decompression routine does. For example, when decompressing a file, we might first encounter a byte with the top bit cleared and the second bit set (i.e. 0b01xxxxxx), which according to the algorithm we reverse-engineered means that we take the lower 6 bits and add 4, then repeat the following byte that number of times (e.g., if we encounter 43 05 in the compressed buffer, we would write seven 05 bytes to the decompressed buffer). So, when compressing, we look for four or more repeated bytes in a row – if we encounter that repetition, then we encode the control byte followed by the repeated byte (e.g., if we encounter 05 05 05 05 05 05 05 in the decompressed buffer, we would write 43 05 to the compressed buffer).
That’s basically the whole process. It gets quite complicated for the “sliding dictionary” that’s characteristic of LZ compression (which I call lookbacks in my code). For those, I essentially keep a running dictionary of every four byte sequence in the file and check to see if the current four byte sequence is in that dictionary. If it is, I insert the control code for the lookback sequence into the compressed buffer.
Finding Filenames
I told a lie of omission about the archive header – there’s more than just the magic integer section! If you scroll down past the magic integers, there’s another section the same length as the previous section and then a section past that which didn’t have a clearly-defined length but whose entries did seem tantalizingly patterned. For basically the entire development of the Chokuretsu utilities, I ignored these two sections entirely – literally skipping over them in the code.

As I was writing the previous post, I took another look at the latter of these two sections as I found it fascinating. Clearly there was something here – early on, I had commented that these could be filenames, but obviously they appeared to be nonsense…right?
Now that I was pretty far into the project, though, I had a lot of knowledge at my disposal. I recalled that some of the event files had titles in them like EV1_000.
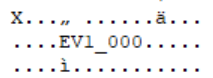
So, on a whim, I took all of the “filenames” out and started doing a find/replace in VS Code one letter at at time. Pretty quickly, it became apparent that these were in fact filenames, just ciphered. I wrote a quick routine to decode them and suddenly, browsing through files got a bit easier!
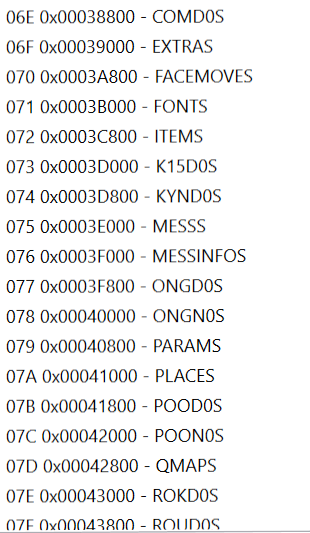
Other Random Things
The Unhinged File Length Routine Revealed
Something else fun: after the second blog post, a person named Ethanol dropped into the Haroohie Discord server and dropped the bomb on what the unhinged file length routine actually does:

Yup! But I noticed something that I’m not sure it’s been brought up before about the “unhinged file length routine”
And I wanted to mention it
Jonko just remade division with his implementation :P
The unhinged function is just a fast integer division function the compiler did
That’s right, it’s just division. 🙃 I’ve tested this since then and indeed, that’s what it is. A bit faster to just divide than to do my weird thing haha.
At the recommendation of my editor, I’d like to take this opportunity to apologize to the Chokuretsu devs, who were not, in fact, fucking with me specifically in this particular instance.
Hardcoded Max File Length
One problem we ran into soon after we had the archive decoded was that the game started crashing when attempting to load one of the earliest event files. As we’ll get into in later posts, the event files necessarily become longer after we edit them. After a lot of investigation, it turned out that we were running into a problem where the game had a hardcoded max file length that we were exceeding. This is something that was outside of the archive entirely and coded as a constant in the actual game code. There were four places where it was coded, but here’s one:
RAM:02033F00 MOV R0, #0x12000
RAM:02033F04 BL sub_202E1C8
In a later post, we’ll cover how we do assembly hacking, but in short this required an assembly hack to fix as we had to patch in a new file length:
ahook_02033F00:
mov r0, #0x16000
bx lr
All this does is change that max length from 0x12000 to 0x16000. An easy fix, but nonetheless an annoying problem to have to find!
See You Soon!
This is a shorter post, but I wanted to make sure I addressed some of the stuff that I left unsaid in the previous posts. Please look forward to the next posts in the series that will delve into how I reverse-engineered specific game files!