《串联》ROM 破解挑战第 2 部分:归档文件考古学
在上一次,我们讨论了我如何对《凉宫春日的串联》中使用的压缩算法进行逆向工程。今天,我们来看看包含在《串联》文件中的归档文件。请注意,虽然我通常会尽量将这些博客文章分开,但这篇文章绝对是建立在我们上次讨论的概念之上的,所以我强烈建议您先阅读它!此外,如果您是从上篇文章来到这里的,请注意,这篇文章有点长,包含更多的程序集!
由于 zip 文件数量的激增,你可能已经熟悉了归档文件:它们是包含文件的文件,通常保存了压缩的版本,以帮助节省磁盘空间。常见的归档文件包括 .zip、.rar、.7z 和 .tar.gz 文件。《串联》使用了扩展名为 .bin 的自定义归档文件格式。由于 Shade 是《串联》的开发商,这些文件也可以被称为“Shade 二进制归档文件”或简称为“二进制归档文件”。让我们选择一个归档文件开始研究。
为了方便起见,让我们选择包含了上次所查看的文件的归档文件。我们可以在 CrystalTile2 中打开游戏,并导航到我们上次看到的位置……
在左下角,它告诉我们这个数据包含在 evt.bin 中(这也是我们可能已经猜到了的,因为它是字符串数据)。
检查 evt.bin
不过,在我们用十六进制编辑器打开它之前,让我们谈谈我们希望在归档文件中看到什么(以确认 evt.bin 确实是一个归档文件)。以下是我要列出的属性:
- 归档文件中的文件数量
- 归档文件中的文件列表,包括文件名和偏移量
- 所有文件的文件数据
关于第二个的快速解释——文件名不言自明,偏移量是指文件中数据所在的位置。简单来说:
- 地址(address)是数据在内存中的绝对位置。当我们在调试器中设置内存断点时,我们使用地址。
- 偏移量(offset)是文件中数据的相对位置。当我们在十六进制编辑器中打开一个文件时,我们会讨论偏移量。
- 指针(pointer)是指向地址或偏移量的值。指向地址的指针可能看起来像值为 0x0220B4A8 的整数,而指向偏移量的指针可能简单到 0x3800。地址由程序在访问内存时使用,而偏移量在文件中使用(因为它们可以加载到内存中的任意位置),因此由程序本身将这些偏移量转换为地址。
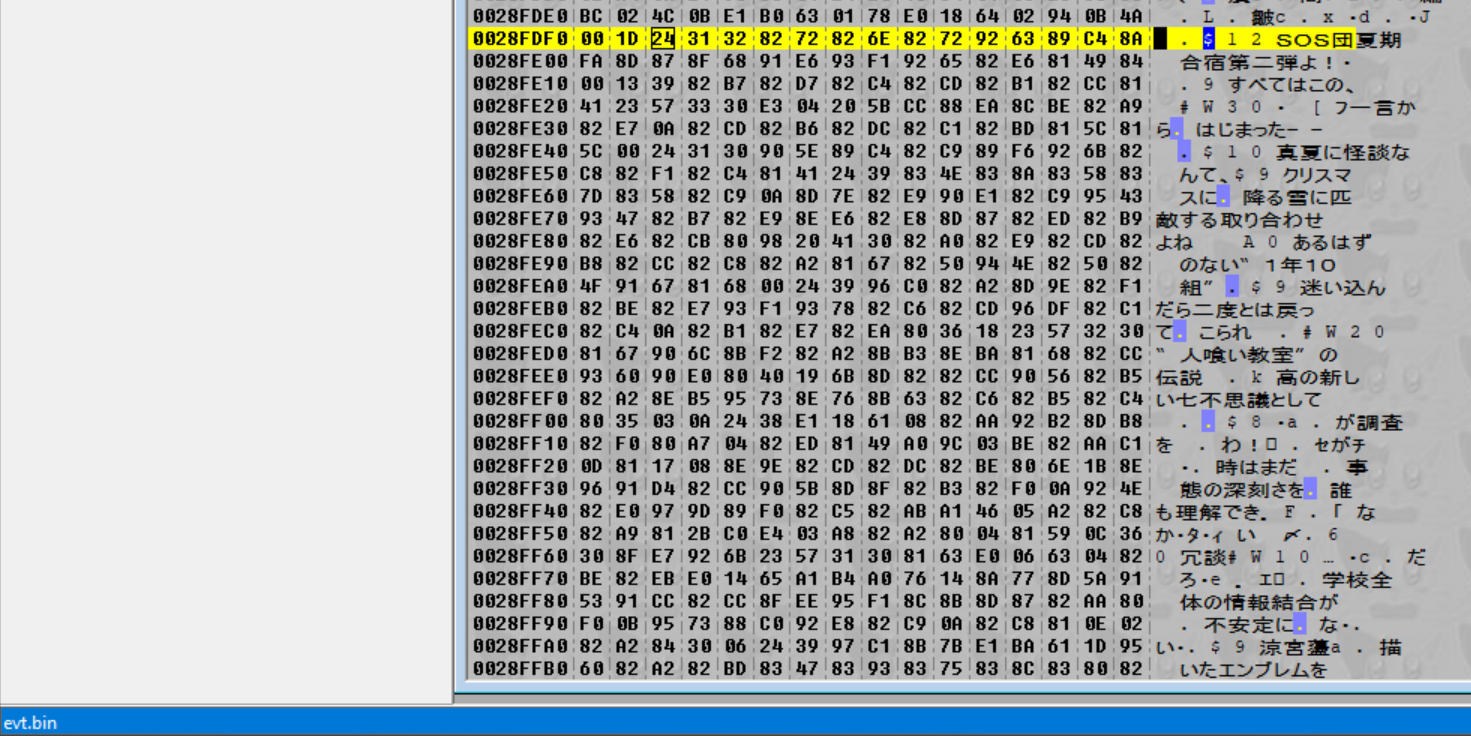
既然这样,让我们打开 evt.bin。我们要做的第一件事是向下滚动一点,以了解这个文件的布局……

有趣!当我们滚动经过一大块数据后,我们最终会进入一个包含 0 的区域,然后是另一大块数据,然后是一个包含 0 的区域,以此类推。更重要的是,当我们滚动过第一段之后,每一大块数据似乎都以 0x800 的倍数开始(很难从两个图像中获得这种感觉,但相信我,如果你打开文件,你就会看到这种模式)。对我来说,这看起来像文件数据——而且,每个文件之间都有整齐的填充。
让我们回到文件的顶部——再说一遍,有很多数字,但这里有一些模式。但在我们看一下青色高亮的数字之前,先来快速解释一下字节序。到目前为止,我们主要考虑的是字节,字节的值可以在 0(0x00)到 255(0xFF)之间。但是,当我们需要表示比这更大的整数时呢?当我们需要这样做时,我们使用多字节整数。常见的类型包括:
| 字节数量 | 正式名字 | C# 名字 |
|---|---|---|
| 2 | 16 位整数 | short(有符号)或 ushort(无符号) |
| 4 | 32 位整数 | int(有符号)或 uint(无符号) |
| 8 | 64 位整数 | long(有符号)或 ulong(无符号) |
然而,有两种可能的方式来存储 16 位整数。以 512(0x200)为例。你可以选择将最高有效字节先存储(即 02 00)或最低有效字节先存储(即 00 02)中。这种决定被称为字节序(endianness),其中前者是“大端序”(big-endian),后者是“小端序”(little-endian)。通常,做出这个决定只是为了与体系结构使用的任何东西保持一致;ARM 是一个小端序体系结构,所以这些文件也可能是小端序的。
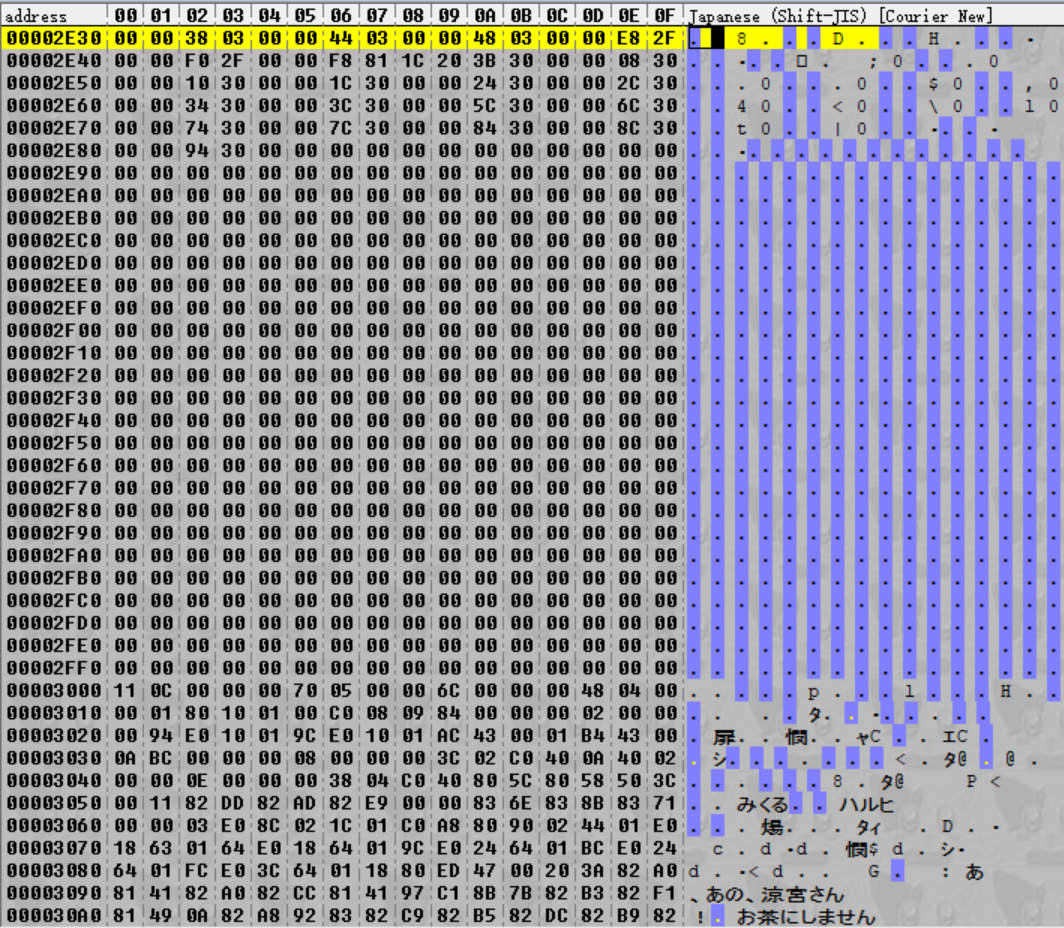
回到上图中的青色高亮,我们可以看到,如果我们将高亮显示的值解释为 16 位的小端序整数,我们会得到如下序列:
0x000A, 0x000C, 0x000E, 0x0010, 0x0014, 0x0016, 0x0018, 0x001A, 0x001C, 0x001E, 0x0020, 0x0022 …
随着我们继续前进,这些整数正在增加!事实上,它们继续增加 0x900 字节,模式终止于最后一个整数 0x94E:
这些绝对不是文件偏移量(它们之间的差异太小了——例如,偏移量 0xB2E 和 0xB32 之间的文件只有 4 个字节长),但它们可能会以某种方式映射到文件偏移量,因为它们正在稳步增加。这意味着每个文件可能有一个这样的值——那么有多少呢?值为两个字节长,间隔两个字节,每次迭代总共四个字节。序列从 0x20 开始,到 0x950 结束。因此:
(0x950 - 0x20) / 0x04 = 0x24C
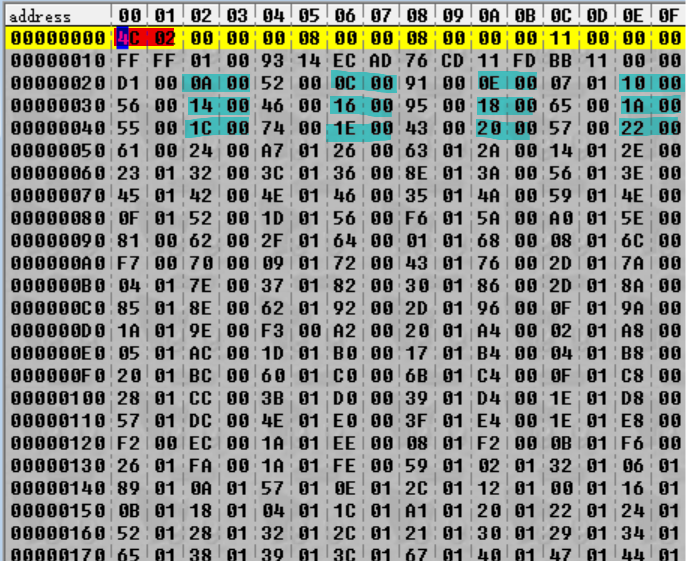
哦!看这个!0x24C 恰好是文件中出现的第一个数字(以红色突出显示)。因此,我们可以猜测第 1 个数字是归档文件中的文件数。(为了二次确认,我们应该检查其他归档文件的模式是否一致——事实确实如此。)
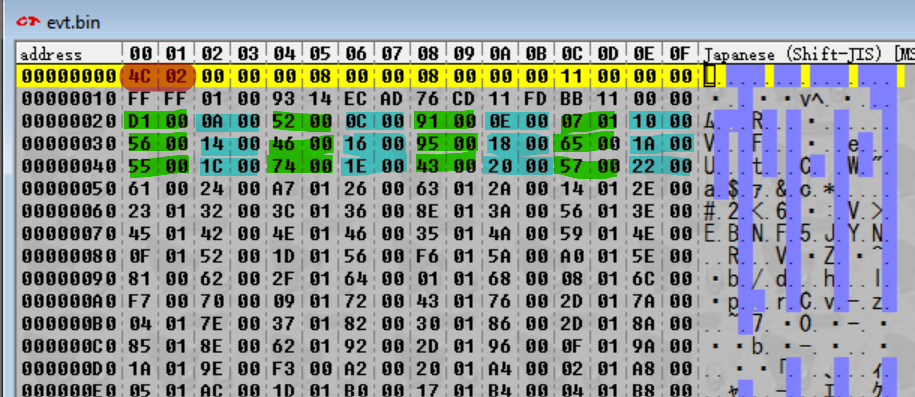
那么,青色高亮显示旁边的数字——上面用绿色高亮显示的数字是什么呢?现在很难说,因为没有明显的模式。然而,我们在这里需要一些命名法,所以我将把绿色和青色高亮的组合称为魔数(magic integer),因为它们是模糊的(magic),但起着重要的作用(也是 magic)。第一个魔数从 0x20 到 0x23,这就是为什么它们是“整数”(interger)——准确来说,32 位整数。
深入其中,重演
上一节的目的是演示如何:a) 确定文件是归档文件;b) 使用一些基本的模式匹配开始对归档文件进行逆向工程。然而,这个归档文件有点奇怪和模糊——虽然大多数归档文件可能只是在头部加入了一个表,其中包含了每个文件的文件名和偏移量(在归档文件中的位置),但这个归档文件显然没有。这些信息在某种程度上被隐藏了。有多种方法可以解决这个问题,但对我来说,最简单的选择似乎是再次回到汇编中。
文件表加载
首先,我们应该尝试找到解析这些归档文件的代码。要做到这一点,我们将执行与上次基本相同的过程——我们将进行内存搜索,以在内存中找到归档文件的文件头(文件的顶部,在归档文件中的文件数据之前),在该内存地址设置读取断点,并查看哪些代码使用了归档文件的文件头。
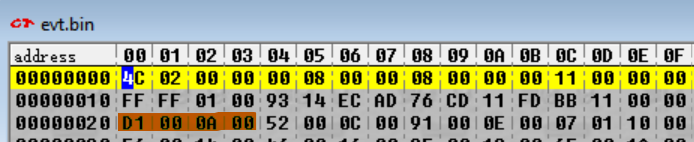
因此,我们回到 DeSmuME,搜索偏移量 0x20 处的四个字节(记住,DeSmuME 的内存搜索要求按相反的顺序输入字节,因此我们输入的不是 D1 00 0A 00,而是 00 0A 00 D1)……
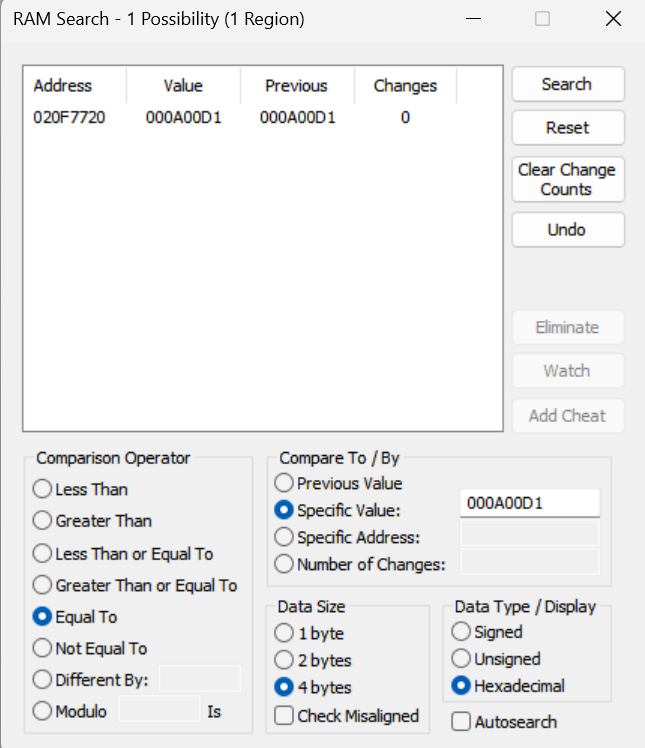
我们又一次找到了一个匹配。所以,让我们打开内存查看器,转到 0x020F7720……
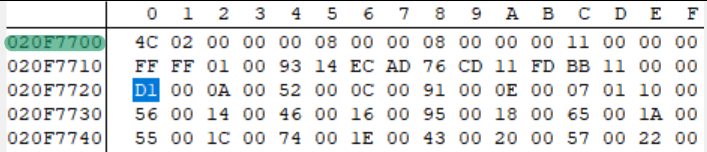
它与 evt.bin 的文件头完全匹配!这意味着 evt.bin 的文件头被加载到了 0x020F7700 中。所以现在,我们将在 No$GBA 中加载游戏(我上次使用 No$ 的时候有点吃力,但它的调试工具确实非常方便),并为 0x020F7700 设置一个读取断点。
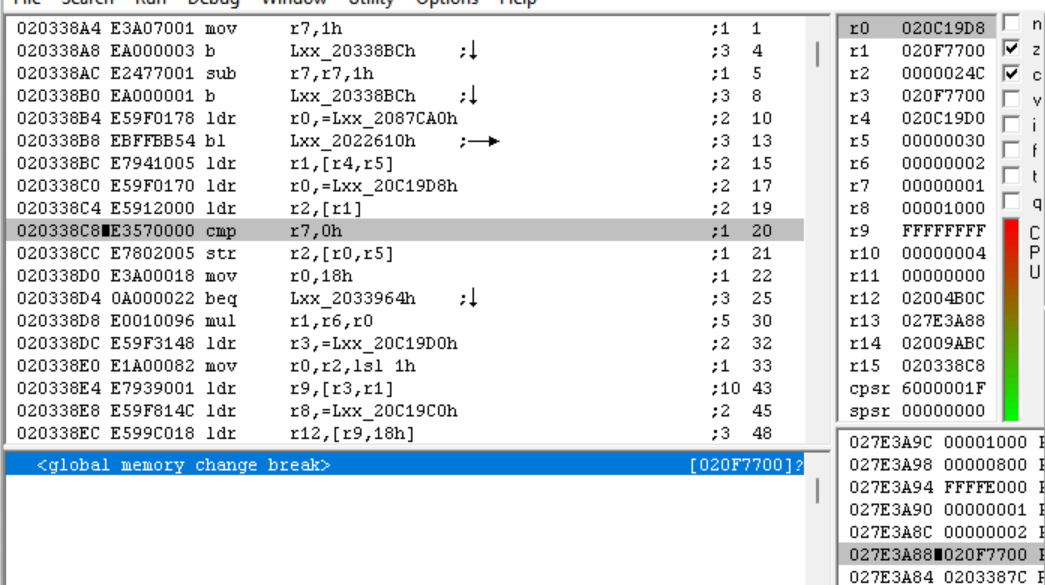
很好,游戏一加载,我们就命中了断点。这意味着归档文件的文件头是在启动时加载的。让我们在 IDA 中调出这个子程序。
RAM:02033818 PUSH {R3-R9,LR}
RAM:0203381C LDR R2, =dword_20A9AB0
RAM:02033820 MOV R6, R0
RAM:02033824 LDR R1, [R2]
RAM:02033828 LDR R0, =aFiletblLoadSta ; "--- filetbl_load start <%d> ---\n"
RAM:0203382C ADD R1, R1, #0x3F ; '?'
RAM:02033830 BIC R3, R1, #0x3F
RAM:02033834 MOV R1, R6
RAM:02033838 STR R3, [R2]
RAM:0203383C BL dbg_print20228DC
我们找到了一些有用的东西!你可以看到的 "--- filetbl_load start <%d> ---\n" 字符串是可执行程序(arm9.bin)本身中硬编码的文本。
=aFiletblLoadSta 是 IDA 为保存该字符串的地址命名的名称,因此 LDR R0, =aFiletblLoadSta 将该字符串的名称加载到 R0 中。在 ARM 汇编中调用另一个子程序时,R0 被用作第一个参数,因此下面的 BL(branch-link,分支链接,或称为“调用此子程序”)将其用作参数。因为这个字符串看起来很像调试字符串,我们可以猜测这个函数是一个调试打印函数(为了调试的目的,它会将文本打印到控制台),这就是为什么我们将这里的函数重命名为 dbg_print20228DC。
但更重要的是,这个调试字符串被打印到这里的事实告诉我们,这个函数的名称在原始源代码中是什么:filetbl_load()。由此,我们可以推测,这个函数的目的是从归档文件中加载“文件表”(file table)——也就是说,它加载了我们刚刚看到的文件头,而该文件头正是我们认为的文件列表!这个技巧(查看调试或错误字符串以了解函数的作用)是我经常使用的东西——甚至不用详细检查反汇编,我们现在就对这个函数的作用有了很好的了解。
加载魔数
在尝试像我们分析解压缩程序时那样分析这个程序之后,我发现这个程序有点抽象。它引用了一堆内存地址和其他我没有任何上下文的东西——所以让我们获取一些上下文,看看它在调试器中做什么。毕竟,我们在这里的目标不一定是对这个程序所做的事情进行逆向工程(与解压缩程序不同),而是使用这个程序来理解归档文件的结构。
所以,回到 No$GBA。单步执行,我们来到这个 STR 指令。STR R2,[R0, R5] 将 R2 的值(0x24C,我们怀疑是文件数)存储在内存位置 R0+R5 中。
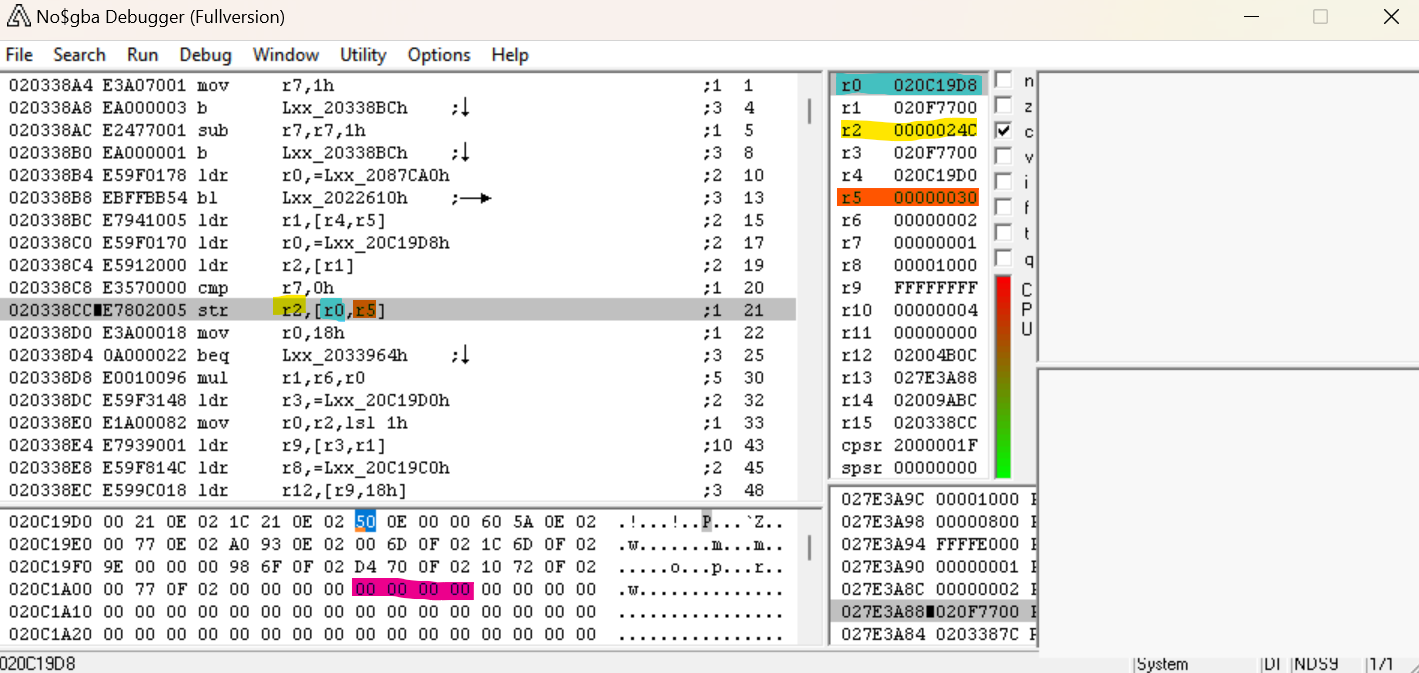
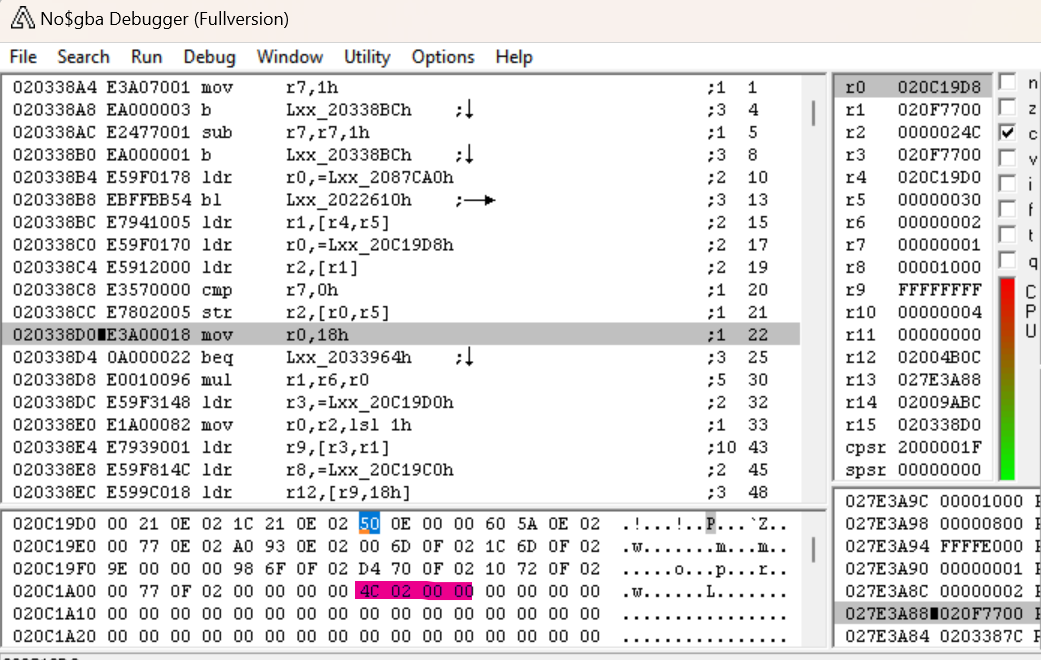
在我们执行过该指令之后,我们实际上可以看到 0x24C 被存储在 0x20C1A08 中,就像我们所期望的那样。现在,让我们为该地址设置一个读取断点,看看它在哪里被引用。
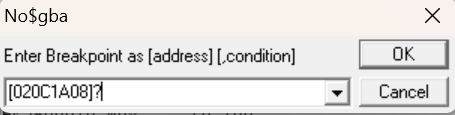
我们运行这个游戏……
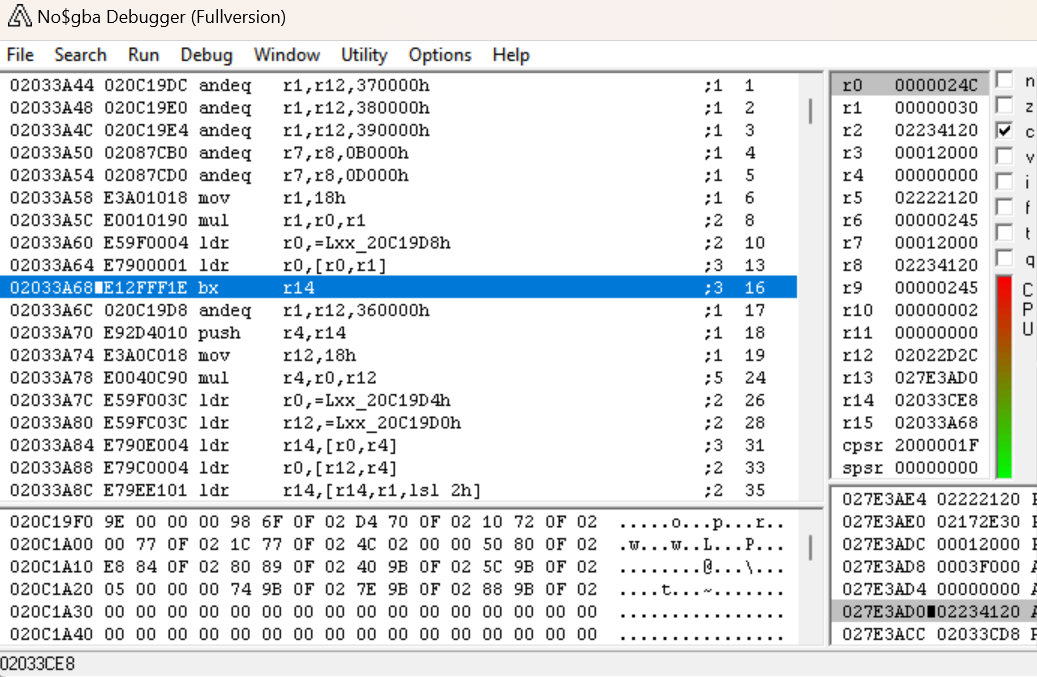
并在这个新的子程序停止。在 IDA 中导航到这个程序会发现它非常短。
RAM:02033A58 sub_2033A58
RAM:02033A58 MOV R1, #0x18
RAM:02033A5C MUL R1, R0, R1
RAM:02033A60 LDR R0, =dword_20C19D8
RAM:02033A64 LDR R0, [R0,R1]
RAM:02033A68 BX LR
BX LR 让我们返回到调用此处的子程序,因此,如果我们知道前一条指令是将 0x24C 加载到 R0(经常用作返回值的寄存器)的指令,我们可能能够假设该子程序的全部目的是从内存加载该值。因此,让我们将此函数重命名为 arc_getNumFiles,然后单步执行,看看是什么调用了它。
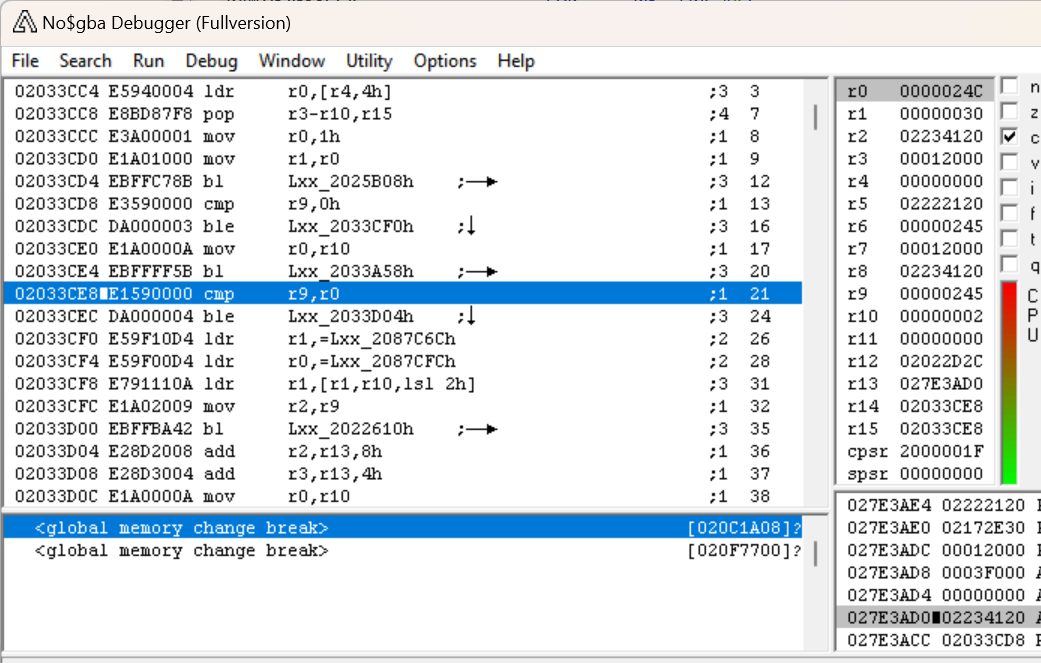
让我们在 IDA 中弹出此子程序的这一部分:
RAM:02033CCC loc_2033CCC
RAM:02033CCC MOV R0, #1
RAM:02033CD0 MOV R1, R0
RAM:02033CD4 BL sub_2025B08
RAM:02033CD8 CMP R9, #0
RAM:02033CDC BLE loc_2033CF0
RAM:02033CE0 MOV R0, R10
RAM:02033CE4 BL arc_getNumFiles
RAM:02033CE8 CMP R9, R0
RAM:02033CEC BLE loc_02033D04
RAM:02033CF0
RAM:02033CF0 loc_2033CF0
RAM:02033CF0 LDR R1, =sArchiveFileNames
RAM:02033CF4 LDR R0, =aFileIndexError ; "file index error : [%s],idx=%d\n"
RAM:02033CF8 LDR R1, [R1,R10,LSL#2]
RAM:02033CFC MOV R2, R9
RAM:02033D00 BL dbg_printError
请记住,在 arc_getNumFiles 中,R0 被设置为(我们猜测是)文件数。我们可以看到它随后立即与 R9 进行比较,如果它小于或等于 R9,我们就在跳转到我展示的部分的末尾。因此,让我们将注意力集中在 R9 上——早些时候,我们可以看到 R9 也与 0 进行了比较,如果它小于或等于零,则跳转到 loc_2033CF0。如果 R9 大于 R0,我们将跳转相同的位置。如果检查该部分,我们可以看到另一条调试消息——"file index error : [%s],idx=%d\n"(文件索引错误)!对于不熟悉 C 语言的人介绍一下,这是格式化字符串——%s 和 %d 表示要插入到字符串中的参数。%s 需要字符串(string),%d 需要十进制数字(decimal)。根据字符串指示发生错误的事实,我们确定 BL 要跳转到的函数是“打印调试错误消息”的函数,该字符串为我们提供了更多的线索。因此,在较高的级别上,这一节将检查 R9 是否大于 0 并且小于或等于文件数。如果不是,则抛出错误。
在高级语言中调用函数时,可以指定传递给函数的参数。在 ARM 汇编中,通过将特定寄存器设置为特定值来传递这些参数——第一个参数设置为 R0,第二个参数设置为 R1,等等。因此,我们知道这个 dbg_printError 子程序将打印该格式的字符串。字符串本身被加载到 R0 中,这意味着第一个参数是字符串本身。下一个参数(对应于 %s)应加载到 R1 中,最后一个参数应加载到 R2 中(对应于 %d)。
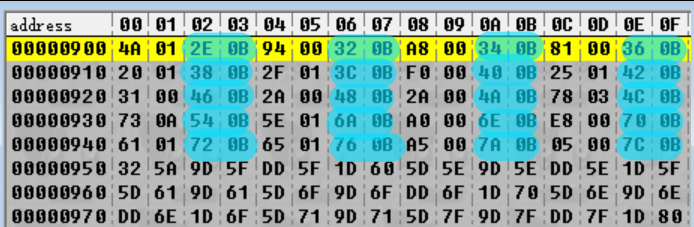
我已经将加载到 R1 中的值标记为了 =sArchiveFileNames——如果我们在 IDA 中跳转到该地址,我们可以看到原因:

这是一个包含了四个归档文件名称的列表!因此,LDR R1,[R1, R10, LSL#2] 这行将会加载的归档文件的名称。如果我们在前面的屏幕截图中查看 R10,我们可以看到它被设置为 2。通常,数组从索引 0 开始,因此这意味着这里的索引 2 将是 aEvtBin——也就是说 %s 的值是 EVT.BIN!
下一行是 MOV R2,R9,它将 R9(我们之前感兴趣的寄存器)的值加载到 R2 中。从错误消息的文本中,我们可以得出结论,R9 存储了文件的索引,即我们在归档文件中加载的文件的位置!我们还知道,我们认为的值确实是归档文件中的文件数量。此外,根据导致错误消息的条件,我们还可以得出这样的结论:文件索引从 1 开始,到归档文件长度结束(而不是像在计算机中更常见的那样从 0 开始,到 length - 1 结束)。
解析魔数
让我们继续:
RAM:02033D04 loc_2033D04
RAM:02033D04 ADD R2, SP, #8
RAM:02033D08 ADD R3, SP, #4
RAM:02033D0C MOV R0, R10
RAM:02033D10 MOV R1, R9
RAM:02033D14 BL sub_2033A70
我们使用以下参数调用 sub_2033A70:
- R0:归档文件的编号(2 =
evt.bin) - R1:归档文件中文件的索引
- R2:一个地址
- R3:另一个地址
换句话说:
sub_2033A70(2, 0x24C, address1, address2)
让我们深入研究 sub_2033A70。
RAM:02033A70 PUSH {R4,LR}
RAM:02033A74 MOV R12, #0x18
RAM:02033A78 MUL R4, R0, R12
RAM:02033A7C LDR R0, =dword_20C19D4
RAM:02033A80 LDR R12, =dword_20C19D0
RAM:02033A84 LDR LR, [R0,R4]
RAM:02033A88 LDR R0, [R12,R4]
RAM:02033A8C LDR LR, [LR,R1,LSL#2]
RAM:02033A90 LDR R1, [R0,#0xC]
RAM:02033A94 LDR R0, [R0,#4]
RAM:02033A98 MOV R1, LR,LSR R1
RAM:02033A9C MUL R0, R1, R0
RAM:02033AA0 STR R0, [R2]
RAM:02033AA4 LDR R0, [R12,R4]
RAM:02033AA8 LDR R1, [R0,#0x10]
RAM:02033AAC LDR R0, [R0,#8]
RAM:02033AB0 AND R1, LR, R1
RAM:02033AB4 MUL R0, R1, R0
RAM:02033AB8 STR R0, [R3]
RAM:02033ABC POP {R4,PC}
这个子程序不太长,所以我们应该能够弄清楚它在做什么;然而,它从一些内存地址加载了许多位,我不知道这些地址中存储了什么。因此,让我们回到调试器。
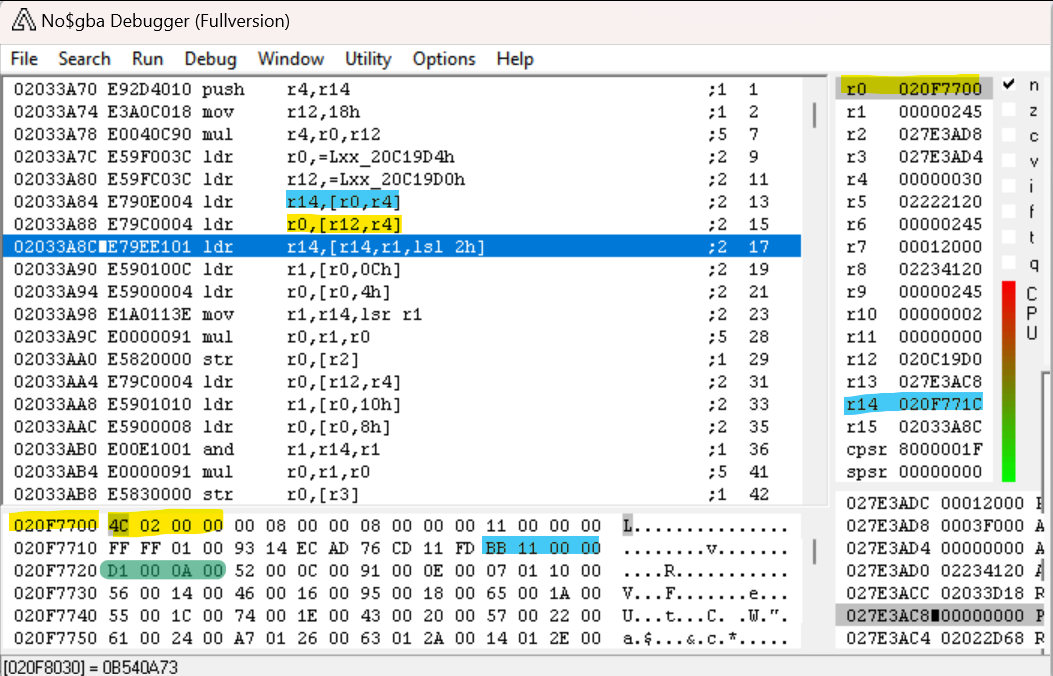
在执行了几个步骤之后,我们可以看到这个子程序的第一部分只是将我们已经找到的 evt.bin 的头部的地址加载到 R0 中。它还将 LR(在 No$GBA 中被称为 R14)设置为第一个魔数(以绿色突出显示)之前的地址(以青色突出显示)。有趣!当前高亮的指令是 LDR LR, [LR,R1,LSL#2]——这条指令把地址 LR + R1 * 4 处的值加载到 LR 中。记住,R1 是文件索引——因此,这将加载与该文件索引对应的魔数!(回想一下,魔数数组从 1 开始,而不是从 0 开始,所以要使其为从零开始的索引,我们需要从第一个魔数之前的地址开始。)
在 C# 中,我们可以将其表示为:
public void sub_2033A70(int archiveNumber, int index, uint address1, uint address2, byte[] archiveBytes)
{
int numFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
uint magicInteger = BitConverter.ToUInt32(archiveBytes.Skip(0x1C + index * 4).Take(4).ToArray());
}
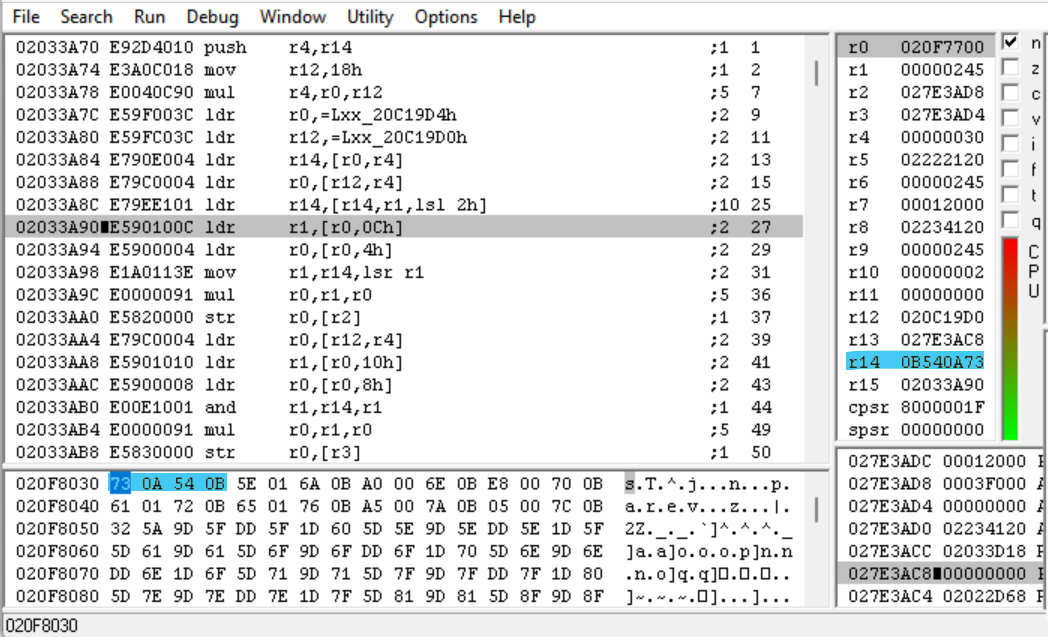
我们应该加载的地址是 0x020F771C + 0x245 * 4 = 0x20F8030,事实上,当我们继续执行时,可以看到该值已加载。现在,魔数已加载,让我们看看接下来会发生什么。
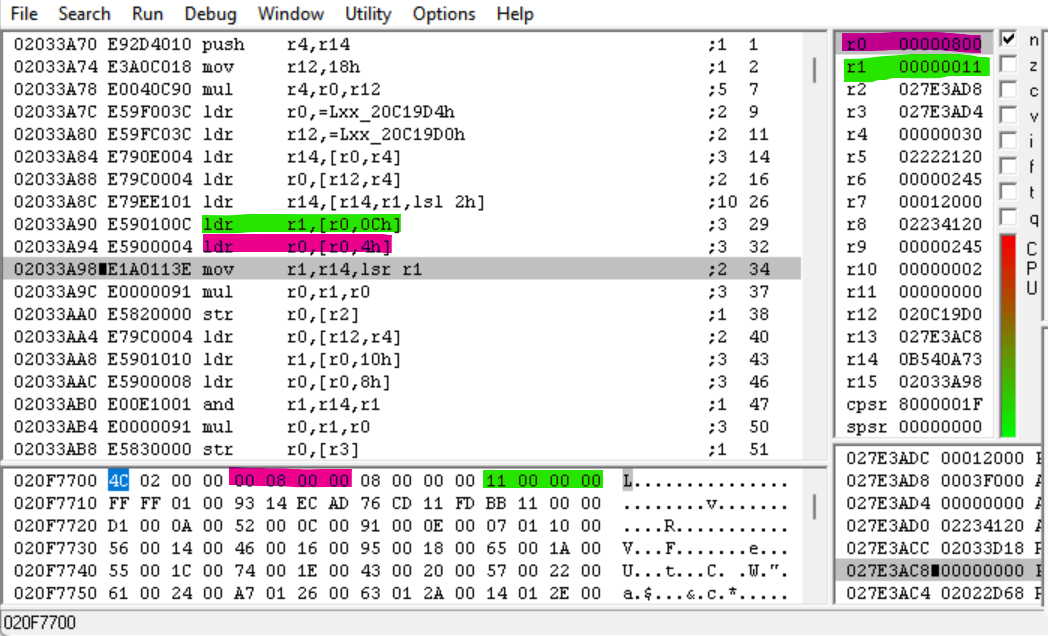
接下来的两条指令将 evt.bin 中偏移量为 0x0C(绿色)和 0x04(粉红色)处的整数分别加载到 R1 和 R0 中。这些指令随后用于某些计算:
MOV R1, LR,LSR R1——该指令将魔数右移 R1(0x11 或 17)的值,并将结果存储在 R1 中。由于魔数是 32 位整数,这步获得了魔数的最高 15 个有效位。MUL R0, R1, R0——该指令将 R1 与 R0(0x800)相乘,并将结果存储在 R0 中。
继续翻译为 C#,得到:
public void sub_2033A70(int archiveNumber, int index, uint address1, uint address2, byte[] archiveBytes)
{
int numFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
uint magicInteger = BitConverter.ToUInt32(archiveBytes.Skip(0x1C + index * 4).Take(4).ToArray());
int msbShift = BitConverter.ToUInt32(archiveBytes.Skip(0x0C).Take(4).ToArray());
int msbMultiplier = BitConverter.ToUInt32(archiveBytes.Skip(0x04).Take(4).ToArray());
uint value1 = (magicInteger >> msbShift) * msbMultiplier;
}
执行完这两条指令后……
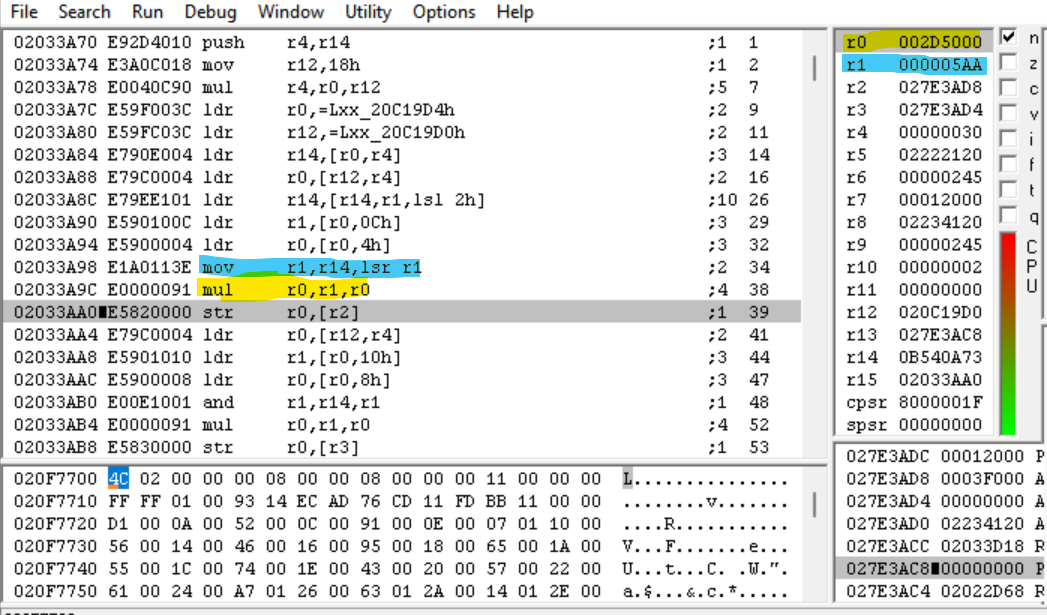
R0 的值现在为 0x2D5000。等一下——我们刚刚将魔数的顶部(我们看到的一直在增加的整数!)乘以 0x800(每个偏移量都可以被其整除)。我们可以计算某个文件偏移量吗?
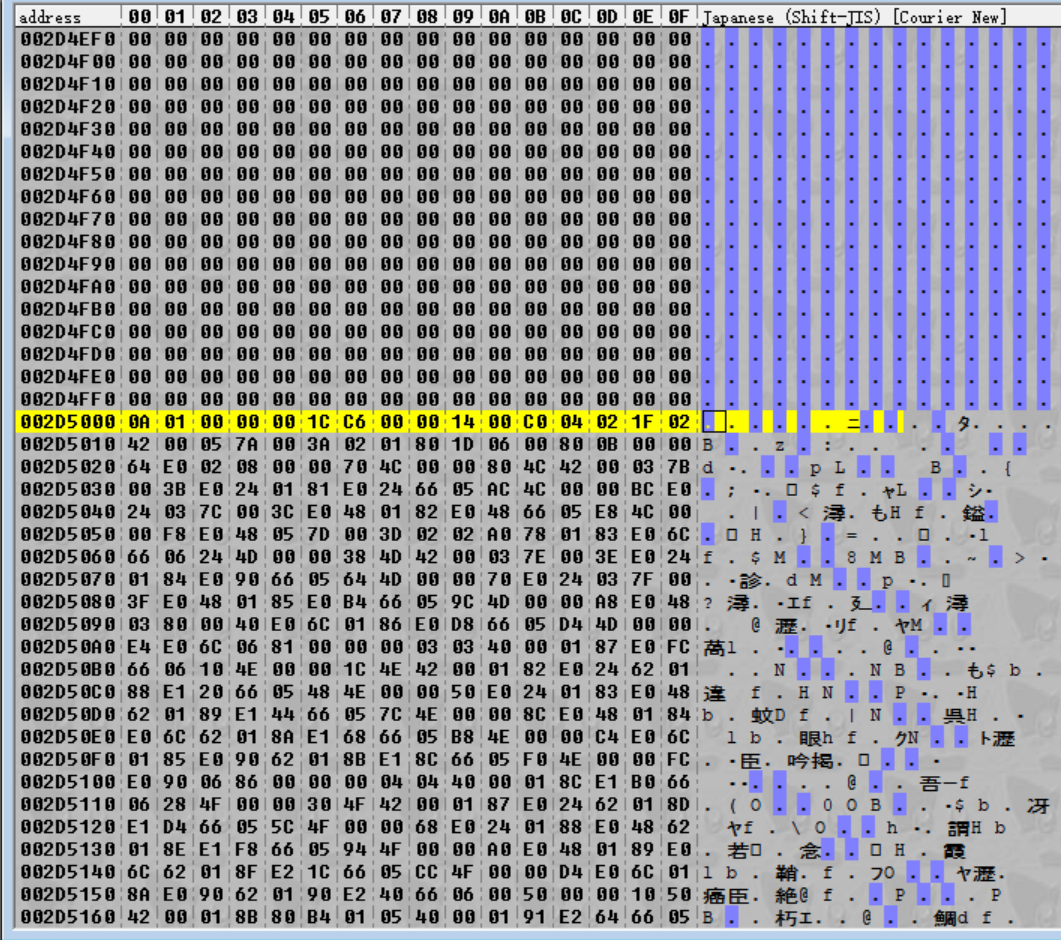
我们确实做到了!我们刚刚找到了计算给定索引的文件偏移量的程序!但是魔数仍然会被加载到 LR 中,所以我们还没有完成。
下一条指令将我们新计算的偏移量存储在内存中。之后的指令再次加载 evt.bin 头部的起始地址。在那之后,有两个与我们之前看到的类似的指令。
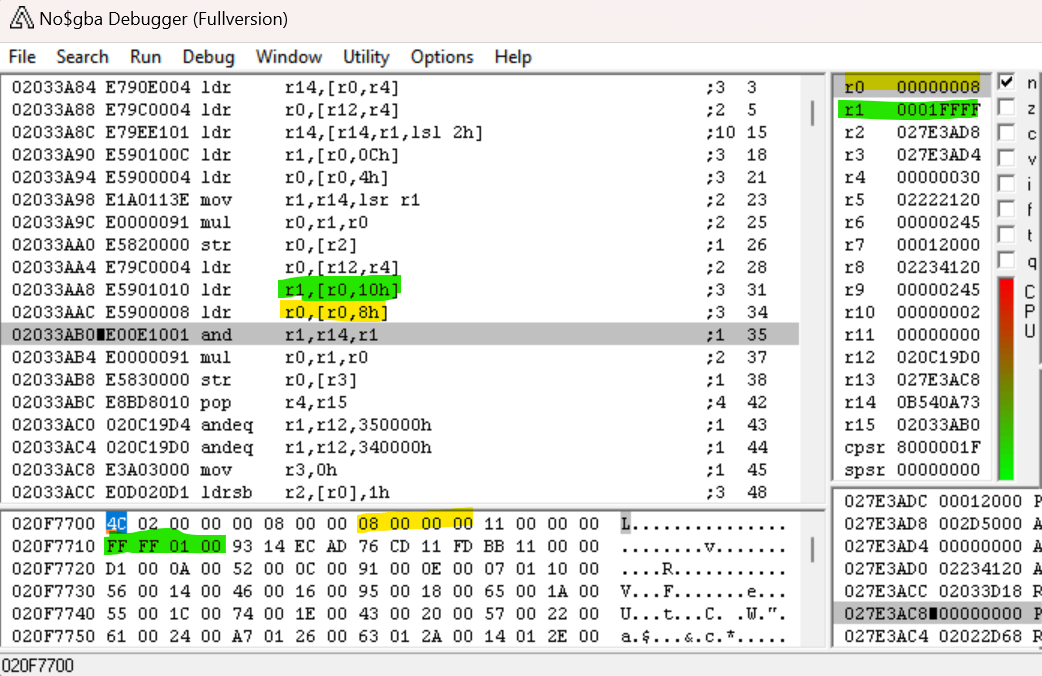
这一次,我们将偏移量 0x10 和 0x08 处的值分别加载到 R1 和 R0 中。我们将再一次使用这些值对魔数进行一些数学运算。
AND R1, LR, R1——该指令将 R1(0x1FFFF)的内容和魔数逐位求和。这有效地得到了魔数的最低 17 个有效位(我们上面计算出的最高 15 个有效位的补码)。MUL R0, R1, R0——该指令将 R1 与 R0(0x08)相乘,并将结果存储在 R0 中。
写成 C#:
public void sub_2033A70(int archiveNumber, int index, uint address1, uint address2, byte[] archiveBytes)
{
int numFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
uint magicInteger = BitConverter.ToUInt32(archiveBytes.Skip(0x1C + index * 4).Take(4).ToArray());
int msbShift = BitConverter.ToInt32(archiveBytes.Skip(0x0C).Take(4).ToArray());
int msbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x04).Take(4).ToArray());
uint offset = (uint)((magicInteger >> msbShift) * msbMultiplier);
int lsbBitwiseAnd = BitConverter.ToInt32(archiveBytes.Skip(0x10).Take(4).ToArray());
int lsbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x08).Take(4).ToArray());
uint value2 = (uint)((magicInteger & lsbBitwiseAnd) * lsbMultiplier);
}
此计算的最终结果为 0x5398。
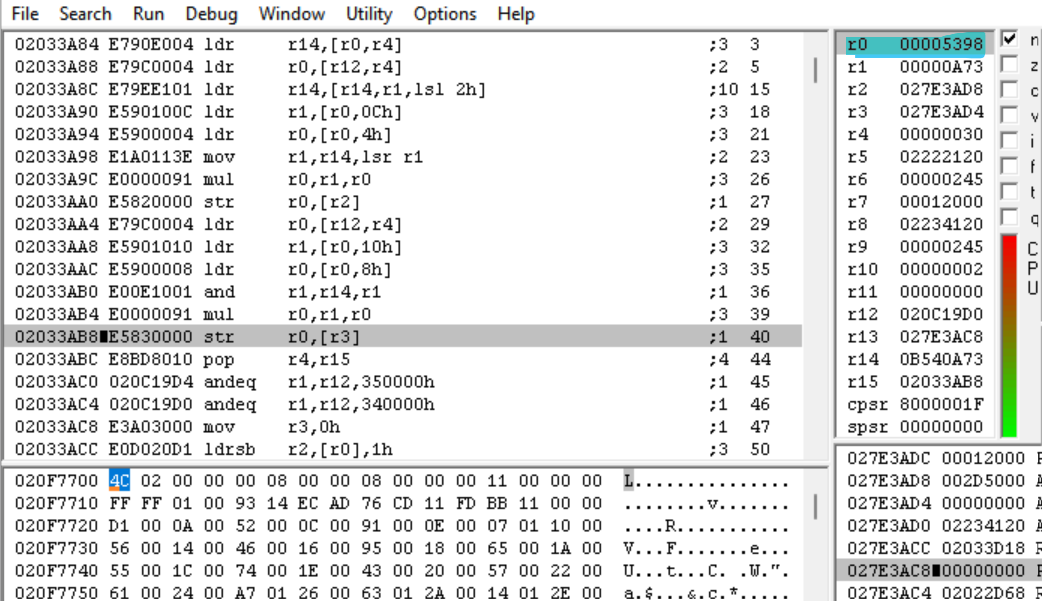
这就是函数的结束。所以我们找到了偏移量,但 0x5398 是什么意思?让我们回到 IDA 中的调用函数,看看我们是否能弄清楚。
RAM:02033D04 ADD R2, SP, #0x30+var_28
RAM:02033D08 ADD R3, SP, #0x30+var_2C
RAM:02033D0C MOV R0, R10
RAM:02033D10 MOV R1, R9
RAM:02033D14 BL arc_processMagicInteger
RAM:02033D18 MOV R0, #0x18
RAM:02033D1C MUL R1, R10, R0
RAM:02033D20 LDR R0, =dword_20C19D0
RAM:02033D24 LDR R6, [SP,#0x30+var_2C]
RAM:02033D28 LDR R0, [R0,R1]
RAM:02033D2C LDR R5, [R0,#4]
RAM:02033D30 ADD R0, R6, R5
RAM:02033D34 MOV R1, R5
RAM:02033D38 SUB R0, R0, #1
RAM:02033D3C BL sub_201D310
RAM:02033D40 MUL R4, R5, R0
RAM:02033D44 ADD R0, R6, #0xFF
RAM:02033D48 ADD R1, R0, #0x300
RAM:02033D4C MOV R0, R1,ASR#9
RAM:02033D50 ADD R0, R1, R0,LSR#22
RAM:02033D54 MOV R0, R0,ASR#10
RAM:02033D58 STR R0, [SP,#0x30+var_30]
RAM:02033D5C LDR R1, =sArchiveFileNames
RAM:02033D60 LDR R0, =aReadSIdxDOfs0x ; "read:[%s],idx=%d,ofs=0x%x,sz=%dKB"
RAM:02033D64 LDR R1, [R1,R10,LSL#2]
RAM:02033D68 LDR R3, [SP,#0x30+var_28]
RAM:02033D6C MOV R2, R9
RAM:02033D70 BL dbg_print20228DC
注意倒数第五行的调试字符串("read:[%s],idx=%d,ofs=0x%x,sz=%dKB")。处理完魔数后,我们得到了一个调试字符串,显式引用了文件索引、偏移量和大小。但是,0x5398 不是这个文件的长度(我们知道它的偏移量,所以我们可以手动检查它的长度;加上填充字节后,文件的长度是 0x5800 字节)。因此,让我们来看看 arc_processMagicInteger 和调试字符串之间的一个子程序调用:sub_201D310。
令人精神错乱的文件长度程序
请小心,这个程序很长。不要担心你不理解所有内容,这对本文的目的来说并不重要。这是一种极其模糊的确定文件长度的方法。
RAM:0201D310 CMP R1, #0
RAM:0201D314 BXEQ LR
RAM:0201D318 CMP R0, R1
RAM:0201D31C MOVCC R1, R0
RAM:0201D320 MOVCC R0, #0
RAM:0201D324 BXCC LR
RAM:0201D328 MOV R2, #0x1C
RAM:0201D32C MOV R3, R0,LSR#4
RAM:0201D330 CMP R1, R3,LSR#12
RAM:0201D334 SUBLE R2, R2, #0x10
RAM:0201D338 MOVLE R3, R3,LSR#16
RAM:0201D33C CMP R1, R3,LSR#4
RAM:0201D340 SUBLE R2, R2, #8
RAM:0201D344 MOVLE R3, R3,LSR#8
RAM:0201D348 CMP R1, R3
RAM:0201D34C SUBLE R2, R2, #4
RAM:0201D350 MOVLE R3, R3,LSR#4
RAM:0201D354 MOV R0, R0,LSL R2
RAM:0201D358 RSB R1, R1, #0
RAM:0201D35C ADDS R0, R0, R0
RAM:0201D360 ADD R2, R2, R2,LSL#1
RAM:0201D364 ADD PC, PC, R2,LSL#2
RAM:0201D368 ; ---------------------------------------------------------------------------
RAM:0201D368 NOP
RAM:0201D36C
RAM:0201D36C loc_201D36C
RAM:0201D36C ADCS R3, R1, R3,LSL#1
RAM:0201D370 SUBCC R3, R3, R1
RAM:0201D374 ADCS R0, R0, R0
RAM:0201D378 ADCS R3, R1, R3,LSL#1
RAM:0201D37C SUBCC R3, R3, R1
RAM:0201D380 ADCS R0, R0, R0
RAM:0201D384 ADCS R3, R1, R3,LSL#1
RAM:0201D388 SUBCC R3, R3, R1
RAM:0201D38C ADCS R0, R0, R0
RAM:0201D390 ADCS R3, R1, R3,LSL#1
RAM:0201D394 SUBCC R3, R3, R1
RAM:0201D398 ADCS R0, R0, R0
RAM:0201D39C ADCS R3, R1, R3,LSL#1
RAM:0201D3A0 SUBCC R3, R3, R1
RAM:0201D3A4 ADCS R0, R0, R0
RAM:0201D3A8 ADCS R3, R1, R3,LSL#1
RAM:0201D3AC SUBCC R3, R3, R1
RAM:0201D3B0 ADCS R0, R0, R0
RAM:0201D3B4 ADCS R3, R1, R3,LSL#1
RAM:0201D3B8 SUBCC R3, R3, R1
RAM:0201D3BC ADCS R0, R0, R0
RAM:0201D3C0 ADCS R3, R1, R3,LSL#1
RAM:0201D3C4 SUBCC R3, R3, R1
RAM:0201D3C8 ADCS R0, R0, R0
RAM:0201D3CC ADCS R3, R1, R3,LSL#1
RAM:0201D3D0 SUBCC R3, R3, R1
RAM:0201D3D4 ADCS R0, R0, R0
RAM:0201D3D8 ADCS R3, R1, R3,LSL#1
RAM:0201D3DC SUBCC R3, R3, R1
RAM:0201D3E0 ADCS R0, R0, R0
RAM:0201D3E4 ADCS R3, R1, R3,LSL#1
RAM:0201D3E8 SUBCC R3, R3, R1
RAM:0201D3EC ADCS R0, R0, R0
RAM:0201D3F0 ADCS R3, R1, R3,LSL#1
RAM:0201D3F4 SUBCC R3, R3, R1
RAM:0201D3F8 ADCS R0, R0, R0
RAM:0201D3FC ADCS R3, R1, R3,LSL#1
RAM:0201D400 SUBCC R3, R3, R1
RAM:0201D404 ADCS R0, R0, R0
RAM:0201D408 ADCS R3, R1, R3,LSL#1
RAM:0201D40C SUBCC R3, R3, R1
RAM:0201D410 ADCS R0, R0, R0
RAM:0201D414 ADCS R3, R1, R3,LSL#1
RAM:0201D418 SUBCC R3, R3, R1
RAM:0201D41C ADCS R0, R0, R0
RAM:0201D420 ADCS R3, R1, R3,LSL#1
RAM:0201D424 SUBCC R3, R3, R1
RAM:0201D428 ADCS R0, R0, R0
RAM:0201D42C ADCS R3, R1, R3,LSL#1
RAM:0201D430 SUBCC R3, R3, R1
RAM:0201D434 ADCS R0, R0, R0
RAM:0201D438 ADCS R3, R1, R3,LSL#1
RAM:0201D43C SUBCC R3, R3, R1
RAM:0201D440 ADCS R0, R0, R0
RAM:0201D444 ADCS R3, R1, R3,LSL#1
RAM:0201D448 SUBCC R3, R3, R1
RAM:0201D44C ADCS R0, R0, R0
RAM:0201D450 ADCS R3, R1, R3,LSL#1
RAM:0201D454 SUBCC R3, R3, R1
RAM:0201D458 ADCS R0, R0, R0
RAM:0201D45C ADCS R3, R1, R3,LSL#1
RAM:0201D460 SUBCC R3, R3, R1
RAM:0201D464 ADCS R0, R0, R0
RAM:0201D468 ADCS R3, R1, R3,LSL#1
RAM:0201D46C SUBCC R3, R3, R1
RAM:0201D470 ADCS R0, R0, R0
RAM:0201D474 ADCS R3, R1, R3,LSL#1
RAM:0201D478 SUBCC R3, R3, R1
RAM:0201D47C ADCS R0, R0, R0
RAM:0201D480 ADCS R3, R1, R3,LSL#1
RAM:0201D484 SUBCC R3, R3, R1
RAM:0201D488 ADCS R0, R0, R0
RAM:0201D48C ADCS R3, R1, R3,LSL#1
RAM:0201D490 SUBCC R3, R3, R1
RAM:0201D494 ADCS R0, R0, R0
RAM:0201D498 ADCS R3, R1, R3,LSL#1
RAM:0201D49C SUBCC R3, R3, R1
RAM:0201D4A0 ADCS R0, R0, R0
RAM:0201D4A4 ADCS R3, R1, R3,LSL#1
RAM:0201D4A8 SUBCC R3, R3, R1
RAM:0201D4AC ADCS R0, R0, R0
RAM:0201D4B0 ADCS R3, R1, R3,LSL#1
RAM:0201D4B4 SUBCC R3, R3, R1
RAM:0201D4B8 ADCS R0, R0, R0
RAM:0201D4BC ADCS R3, R1, R3,LSL#1
RAM:0201D4C0 SUBCC R3, R3, R1
RAM:0201D4C4 ADCS R0, R0, R0
RAM:0201D4C8 ADCS R3, R1, R3,LSL#1
RAM:0201D4CC SUBCC R3, R3, R1
RAM:0201D4D0 ADCS R0, R0, R0
RAM:0201D4D4 ADCS R3, R1, R3,LSL#1
RAM:0201D4D8 SUBCC R3, R3, R1
RAM:0201D4DC ADCS R0, R0, R0
RAM:0201D4E0 ADCS R3, R1, R3,LSL#1
RAM:0201D4E4 SUBCC R3, R3, R1
RAM:0201D4E8 ADCS R0, R0, R0
RAM:0201D4EC MOV R1, R3
RAM:0201D4F0 BX LR
我称之为“令人精神错乱的文件长度程序”。0x5398 这个数字实际上不是实际的压缩后的数组长度,而是被编码后的压缩长度,需要被此程序解码。一个快速的问答:
- 问:为什么这个程序有这么多重复?
答:这是一些编译器(包括 ARM 编译器)的一个名为循环展开的函数的结果。通常情况下,当编译器可以静态地确定编译时将发生多少循环时,会在执行时间与程序空间之间进行权衡。 - 问:这是什么意思?
答:别担心,这其实并不重要。重点是,这是一个循环,所以我们可以把它当作一个循环。 - 问:我看到了很多
ADCS和SUBCC指令。它们是什么意思?
答:ADCS表示“加和并进位,设置标志”。本质上来说,这意味着将两个数字相加,如果上一次运算产生“进位”,我们就在和上加 1。然后,我们根据加和是否导致进位来设置或清除进位标志。这里的“进位”指的是“无符号溢出”——即 32 位整数超过其最大值并循环。SUBCC表示“如果没有进位则相减”。这意味着如果前一个运算没有导致进位,我们令两个数字相减。 - 问:为什么开发者会这样做?
答:他们他妈的给我添麻烦。
走出森林
哇!这里有很多汇编指令。我们可以继续往下看子程序,但我们现在已经完成了主要任务:我们对 Shade 的二进制归档文件的工作原理有了很多了解。如果我们回顾一下我们最初期望的归档文件可能具有的内容列表:
- 我们找到了文件的数量(这是归档文件的前四个字节)。
- 虽然似乎没有明显定位的文件名,但我们确实找到了文件的索引(这似乎是它的查找方式)、偏移量和压缩长度之间的映射。
- 文件数据肯定存在,并且以每 0x800 字节对齐。
很好!这是一个巨大的进步。让我们看看现在是否可以编写一些东西来解析归档文件。
编写我们自己的解析器
让我们从思考如何在 C# 中表示归档文件开始。有四个不同的归档文件,每个归档文件都有自己的文件类型——对我来说,似乎需要编写一个泛型类。首先,我们将创建一个泛型类来表示归档文件中的文件。
public partial class FileInArchive
{
public uint MagicInteger { get; set; }
public int Index { get; set; }
public int Offset { get; set; }
public List<byte> Data { get; set; }
public byte[] CompressedData { get; set; }
public bool Edited { get; set; } = false;
public FileInArchive()
{
}
}
这非常基本——有魔数、索引、偏移量和压缩/未压缩数据的属性。我们还有一个 Edited 属性,用于指示是否修改了文件。最后,有一个空白构造函数——我们将让派生类实现它。
现在制作通用的归档文件:
public class ArchiveFile<T>
where T : FileInArchive, new()
{
public const int FirstMagicIntegerOffset = 0x20;
public string FileName { get; set; } // e.g. evt.bin
public int NumFiles { get; set; }
public int MagicIntegerMsbMultiplier { get; set; }
public int MagicIntegerLsbMultiplier { get; set; }
public int MagicIntegerLsbAnd { get; set; }
public int MagicIntegerMsbShift { get; set; }
public List<uint> MagicIntegers { get; set; } = new();
public List<T> Files { get; set; } = new();
}
所有这些都是我们以前见过的。现在,转到构造函数。
public ArchiveFile(byte[] archiveBytes)
{
NumFiles = BitConverter.ToInt32(archiveBytes.Take(4).ToArray());
MagicIntegerMsbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x04).Take(4).ToArray());
MagicIntegerLsbMultiplier = BitConverter.ToInt32(archiveBytes.Skip(0x08).Take(4).ToArray());
MagicIntegerLsbAnd = BitConverter.ToInt32(archiveBytes.Skip(0x10).Take(4).ToArray());
MagicIntegerMsbShift = BitConverter.ToInt32(archiveBytes.Skip(0x0C).Take(4).ToArray());
for (int i = FirstMagicIntegerOffset; i < (NumFiles * 4) + 0x20; i += 4)
{
MagicIntegers.Add(BitConverter.ToUInt32(archiveBytes.Skip(i).Take(4).ToArray()));
}
在这里,我们只是从文件头提取我们找到的值,然后循环并提取所有的魔数。
在将文件添加到归档文件之前,我们必须转换压缩长度函数。我可以一步一步地浏览并解释我是如何从汇编代码转换过来的,但这将会非常冗长乏味。因此,以下是最终代码:
public int GetFileLength(uint magicInteger)
{
// 完全精神错乱的函数
int magicLengthInt = 0x7FF + (int)((magicInteger & (uint)MagicIntegerLsbAnd) * (uint)MagicIntegerLsbMultiplier);
int standardLengthIncrement = 0x800;
if (magicLengthInt < standardLengthIncrement)
{
magicLengthInt = 0;
}
else
{
int magicLengthIntLeftShift = 0x1C;
uint salt = (uint)magicLengthInt >> 0x04;
if (standardLengthIncrement <= salt >> 0x0C)
{
magicLengthIntLeftShift -= 0x10;
salt >>= 0x10;
}
if (standardLengthIncrement <= salt >> 0x04)
{
magicLengthIntLeftShift -= 0x08;
salt >>= 0x08;
}
if (standardLengthIncrement <= salt)
{
magicLengthIntLeftShift -= 0x04;
salt >>= 0x04;
}
magicLengthInt = (int)((uint)magicLengthInt << magicLengthIntLeftShift);
standardLengthIncrement = 0 - standardLengthIncrement;
bool carryFlag = Helpers.AddWillCauseCarry(magicLengthInt, magicLengthInt);
magicLengthInt *= 2;
int pcIncrement = magicLengthIntLeftShift * 12;
for (; pcIncrement <= 0x174; pcIncrement += 0x0C)
{
// ADCS
bool nextCarryFlag = Helpers.AddWillCauseCarry(standardLengthIncrement, (int)(salt << 1) + (carryFlag ? 1 : 0));
salt = (uint)standardLengthIncrement + (salt << 1) + (uint)(carryFlag ? 1 : 0);
carryFlag = nextCarryFlag;
// SUBCC
if (!carryFlag)
{
salt -= (uint)standardLengthIncrement;
}
// ADCS
nextCarryFlag = Helpers.AddWillCauseCarry(magicLengthInt, magicLengthInt + (carryFlag ? 1 : 0));
magicLengthInt = (magicLengthInt * 2) + (carryFlag ? 1 : 0);
carryFlag = nextCarryFlag;
}
}
return magicLengthInt * 0x800;
}
现在我们得到了一个函数,可以根据文件的魔数来确定文件的压缩长度。但问题是,当我们保存文件时,我们必须将其反转,并从压缩的长度返回到魔数。我们如何做到这一点?
嗯,在某个时候,有人有一个程序可以做到这一点,但我不是那个人。更重要的是,这个函数超出了我的想象,我甚至不知道如何开始尝试对它逆向。但这对我们来说还不是终点——请记住, 0x5398 值的长度只有 17 位。这意味着被编码的整数的可能值(即,对精神错乱的文件长度函数的输入)的范围是从 0 到 0x1FFFF。这只有 131,072 个可能的值,在这一范围内并没有那么多。所以我们只是……根据文件长度计算所有可能的编码值,并将它们添加到字典中。(由于这些值是常量,因此我们在构造函数中只执行一次。)
for (int i = 0; i <= MagicIntegerLsbAnd; i++)
{
int length = GetFileLength((uint)i);
if (!LengthToMagicIntegerMap.ContainsKey(length))
{
LengthToMagicIntegerMap.Add(length, i);
}
}
然后,当我们想要一个新的魔数时,我们只需要:
public uint GetNewMagicInteger(T file, int compressedLength)
{
uint offsetComponent = (uint)(file.Offset / MagicIntegerMsbMultiplier) << MagicIntegerMsbShift;
int newLength = (compressedLength + 0x7FF) & ~0x7FF; // 四舍五入到最接近的 0x800
int newLengthComponent = LengthToMagicIntegerMap[newLength];
return offsetComponent | (uint)newLengthComponent;
}
最后,我们准备好开始解析文件了。我们所要做的就是循环遍历魔树,从魔数中获得文件偏移量和压缩后的长度,然后使用它们来获取文件数据并初始化 FileInArchive 衍生类。
for (int i = 0; i < MagicIntegers.Count; i++)
{
int offset = GetFileOffset(MagicIntegers[i]);
int compressedLength = GetFileLength(MagicIntegers[i]);
byte[] fileBytes = archiveBytes.Skip(offset).Take(compressedLength).ToArray();
if (fileBytes.Length > 0)
{
T file = new();
try
{
file = FileManager<T>.FromCompressedData(fileBytes, offset); // 不用担心这个函数,它所做的只是初始化文件。
}
catch (IndexOutOfRangeException)
{
Console.WriteLine($"Failed to parse file at 0x{i:X8} due to index out of range exception (most likely during decompression)");
}
file.Offset = offset;
file.MagicInteger = MagicIntegers[i];
file.Index = i + 1;
file.Length = compressedLength;
file.CompressedData = fileBytes.ToArray();
Files.Add(file);
}
}
我们现在得到了一个函数解析器。我们可以编写一个快速的 GUI,向我们展示文件加载看起来如何,以及……
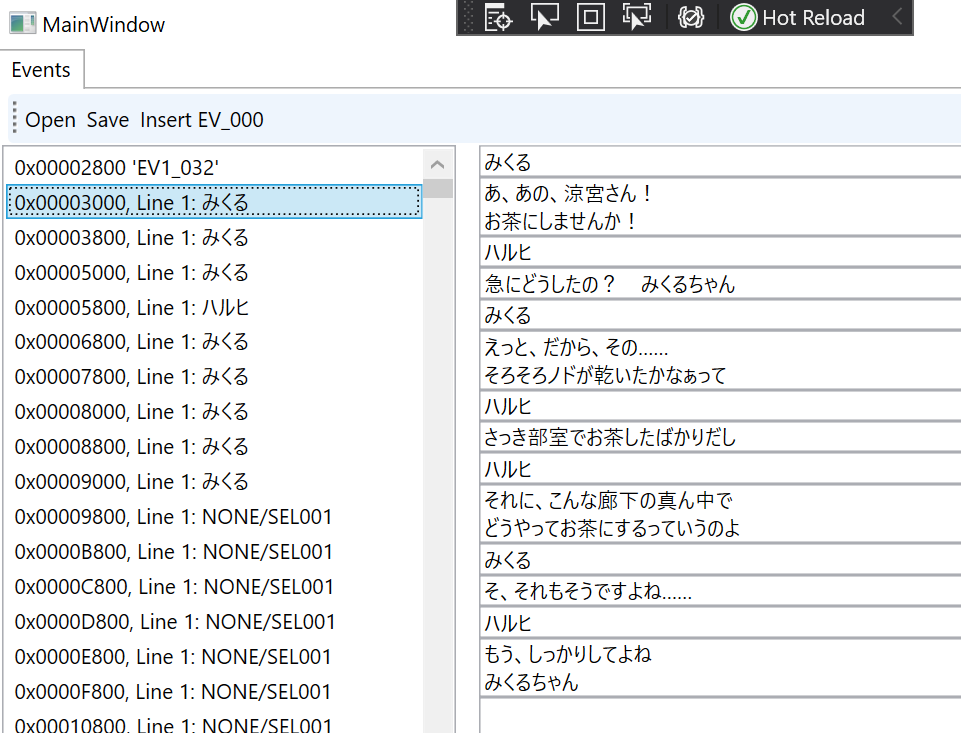
看上去很不错!(右边的文本是对即将到来的事情的预览——我在解析归档文件的同时,也在解析事件/脚本文件,但我不会在这篇文章中讨论事件文件的逆向工程。)所以现在我们可以打开 evt.bin,甚至编辑其中的文件。不过,还有一步——我们必须能够在编辑完二进制归档文件后保存它们。
保存归档文件
保存归档文件的理想方法是从头开始重建,但由于头部中有我们不完全理解的数据,我们将不得不接受在适当的位置编辑文件头。因此,我们首先添加在解析时获取的整个文件头。
public byte[] GetBytes()
{
List<byte> bytes = new();
bytes.AddRange(Header);
接下来,我们将遍历所有文件,并按顺序将它们添加到归档文件中。如果文件没有经过编辑,那么我们将直接将其添加到归档文件中。但是,如果文件已被编辑,我们将不得不压缩已编辑的数据。
for (int i = 0; i < Files.Count; i++)
{
byte[] compressedBytes;
if (!Files[i].Edited || Files[i].Data is null || Files[i].Data.Count == 0)
{
compressedBytes = Files[i].CompressedData;
}
else
{
compressedBytes = Helpers.CompressData(Files[i].GetBytes());
}
bytes.AddRange(compressedBytes);
在这里,我们遇到了一个障碍——在某些情况下,编辑后的文件会比原始文件长,对吧?这种情况会比我们想象中发生得更频繁,因为我的压缩算法的实现明显不如开发人员使用的实现更高效,所以即使解压后的文件保持相同大小,重新压缩的时间也会更长。这个问题的解决方案实际上很简单,只是有点乏味:我们把所有东西都往下移动。
为什么把东西搬下来很乏味?好吧,这又回到了魔数——它们包含了每个文件的偏移量。通过向下移动文件,我们改变了它的偏移量,这意味着魔数也会改变。所以我们需要编写代码来做到这一点。
if (i < Files.Count - 1) // If we aren’t on the last file
{
int pointerShift = 0; // Assume we’re not going to be shifting offsets at all
while (bytes.Count % 0x10 != 0) // ensure our file is 16-byte aligned
{
bytes.Add(0);
}
// 如果我们构建的归档文件的当前大小大于下一个文件的偏移量,
// 这意味着我们需要调整下一个归档文件的偏移量
if (bytes.Count > Files[i + 1].Offset)
{
// 计算我们需要将魔数移动多少
pointerShift = ((bytes.Count - Files[i + 1].Offset) / MagicIntegerMsbMultiplier) + 1;
}
if (pointerShift > 0)
{
// 计算指针移位后的新魔数
Files[i + 1].Offset = ((Files[i + 1].Offset / MagicIntegerMsbMultiplier) + pointerShift) * MagicIntegerMsbMultiplier;
int magicIntegerOffset = FirstMagicIntegerOffset + (i + 1) * 4;
uint newMagicInteger = GetNewMagicInteger(Files[i + 1], Files[i + 1].Length);
Files[i + 1].MagicInteger = newMagicInteger;
MagicIntegers[i + 1] = newMagicInteger;
bytes.RemoveRange(magicIntegerOffset, 4);
bytes.InsertRange(magicIntegerOffset, BitConverter.GetBytes(Files[i + 1].MagicInteger));
}
// 添加文件填充
while (bytes.Count < Files[i + 1].Offset)
{
bytes.Add(0);
}
}
砰。我们得到了能用的代码,可以移动魔数。所以,让我们测试一下——修改一个文件并保存存档,看看是否可以更改一些文本。

我向你展示了我在游戏中编辑的第一段文字。🥰
如果你有兴趣查看归档文件代码的最终结果,你可以在 GitHub 上查看代码!
下一步是什么
我们现在已经成功地解析并重新打包了归档文件。接下来我们要讨论的是我逆向工程的第一个文件:事件文件,其中包含游戏的脚本。但在此之前,我将发布这两篇帖子的附录,其中将包含常见问题的答案,以及关于我们实现这一切所经历的实际过程的一些历史笔记。感谢阅读,敬请期待!