《串联》ROM 破解挑战第 1 部分:破解压缩算法!
大家好!这是一系列博客文章中的第一篇,这些文章将深入探讨翻译《凉宫春日的串联》(涼宮ハルヒの直列)所涉及的技术挑战。这些博客确实很有技术性,包括代码示例等内容,但它们的编写是为了让普通读者能够理解。如果你有任何问题或评论,请随时向我们转推!
整个项目始于在 GBATemp 论坛上的两篇帖子,一位名叫 Cerber 的用户(现在他是我们的图形设计师之一!)请求帮助翻译一款衍生自凉宫春日系列的鲜为人知的 DS 游戏。他在游戏中找到脚本并将其替换为英文字符方面取得了一些进展,但在能够完全重新插入文本方面遇到了困难。
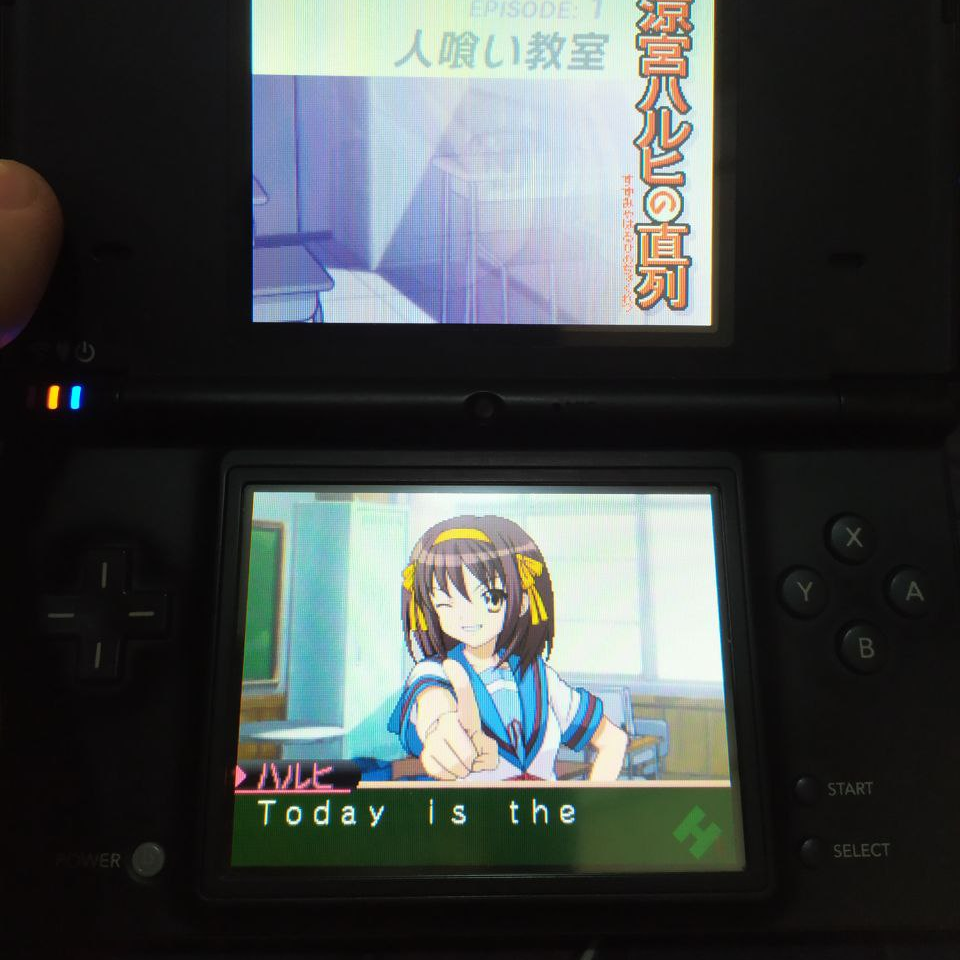
Cerber 所做的正是在十六进制编辑器(一种直接修改二进制文件的工具,其中每个字节都表示为十六进制数)中打开 ROM,并搜索他在游戏中看到的文本。他能够找到脚本,但他遇到的问题是如何处理他所谓的“游戏代码”,该代码围绕着他试图替换的文本——修改用红色标记的部分会让游戏彻底崩溃。

快速解释一下我们在这里看到的内容:在左侧是文件中的原始二进制,用十六进制表示为一系列字节。十六进制(基数为 16)——虽然我们通常使用十进制(基数为 10,即 0、1、2、3、4、5、6、7、8、9),计算机使用二进制(基数为 2,即 0、1),但程序员通常使用十六进制,因为它允许我们用两个字符表示单个字节。在写入数字时,为了区分基数,我们通常使用 0x 作为十六进制数的前缀(0x17 在十进制中是 23),使用 0b 表示二进制数(0b0000_0100 在十进制下是 4)。
右侧的字符表示我们在左侧看到字节,通过编码来解释。你可能熟悉 ASCII,这是最基本的编码——字母表中的每个字母都由单个字节表示。该游戏使用名为 Shift-JIS 的编码,这是 Unicode 出现之前日语的表示方式。
根据我过去的经验,我做了一些调查,然后发布了一个可能不太可靠的回复:
你好!它附近的并不是游戏代码;而是这个场景的更多数据。我还不知道这一切都有什么作用,但我可以告诉你的是,这整个块被压缩了,并且解压缩的子程序位于 0x2026190。你必须先解压缩它,然后才能开始编辑它,如果能够解压的话,我们可能会更加了解每部分是做什么的,这将使我们能够编辑它。
你需要考虑的另一件事是字体宽度的修改(半角或可变宽度)。游戏中有很多行填充了整个文本框,你不可能用全角字符把它塞进去,所以你也要调查一下这个。
让我们一点一点地讨论这个问题。
压缩
我怎么知道这个部分被压缩了?请看他的屏幕截图,我们可以清楚地看到游戏中的文本显示在十六进制编辑器中(我在下面用黄色标记了一个例子),但文本的某些部分缺失了——例如,我在下面标记的“ハルヒの”中的一位(bit)被较短字符序列(高亮为了蓝色)所取代。

这是所谓运行长度编码的一个标志——这是一种压缩文件的方法,专注于消除重复。好的,现在我们知道它被压缩了——下一步该怎么办?嗯,我们知道最终目标是:我们想用英语文本替换文件中的文本。为了做到这一点,我们必须能够自己解压缩文本,以便编辑文件。然而,由于游戏需要被压缩的文本,我们还必须能够重新压缩文件,以便将其重新插入游戏。好了,让我们开始吧。
查找解压缩子程序
实际上有很多信息可供我们使用。我们得到了一个文件,知道它被压缩了,我们很清楚它解压缩后会得到什么,我们知道这个文件在游戏中的哪里被使用。因此,让我们在 DeSmuME(编写本文时具有最佳内存搜索器的模拟器)中加载游戏,并搜索游戏中出现的一些文本。
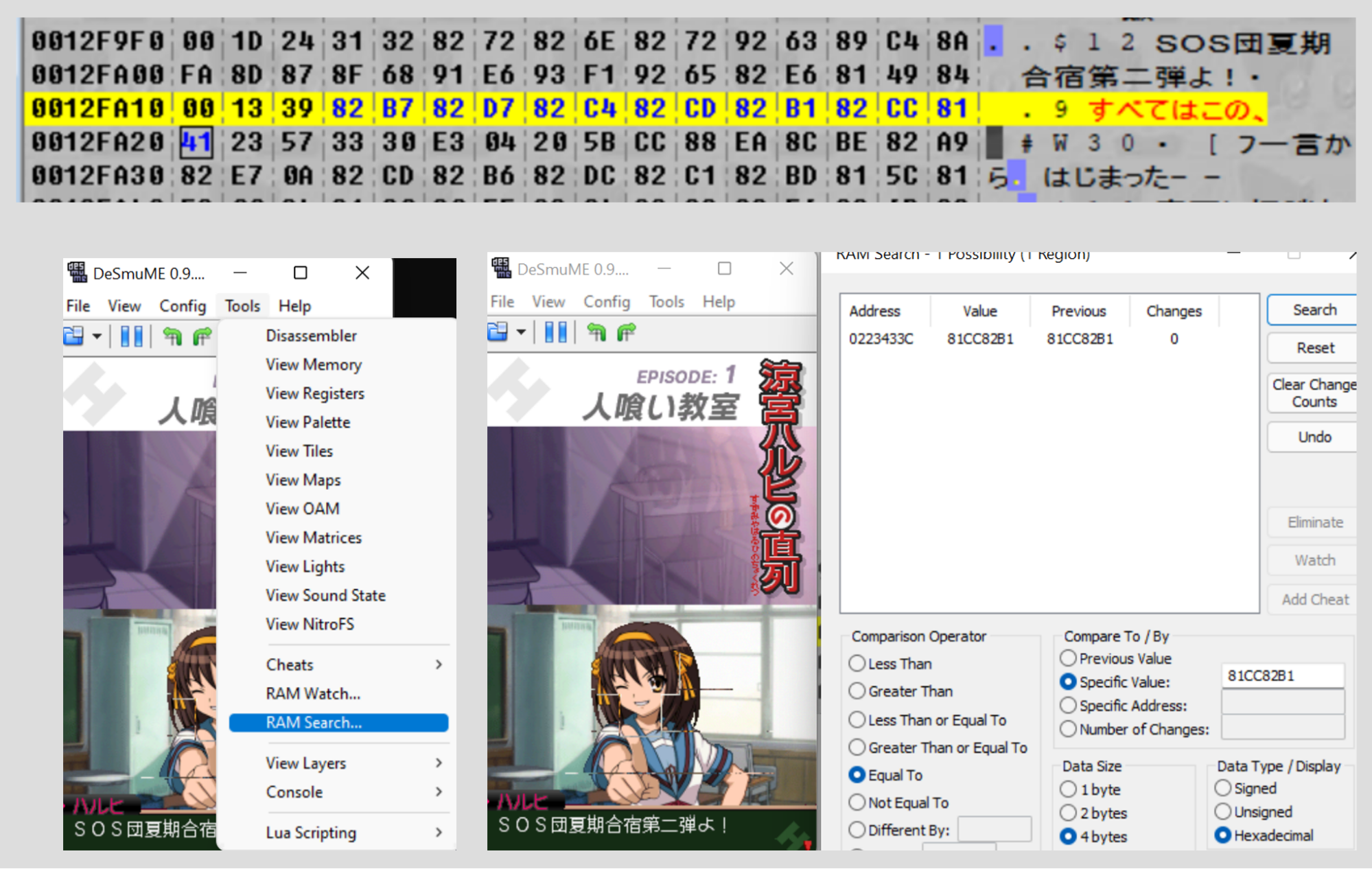
因此,我们搜索 0x81CC82B1(DeSmuME 的 RAM 搜索需要输入与编码顺序相反的数值),它对应于文本中的“この、”。我们在地址 0x0223433C 处正好找到一个结果——非常棒。我们转到这个内存地址……
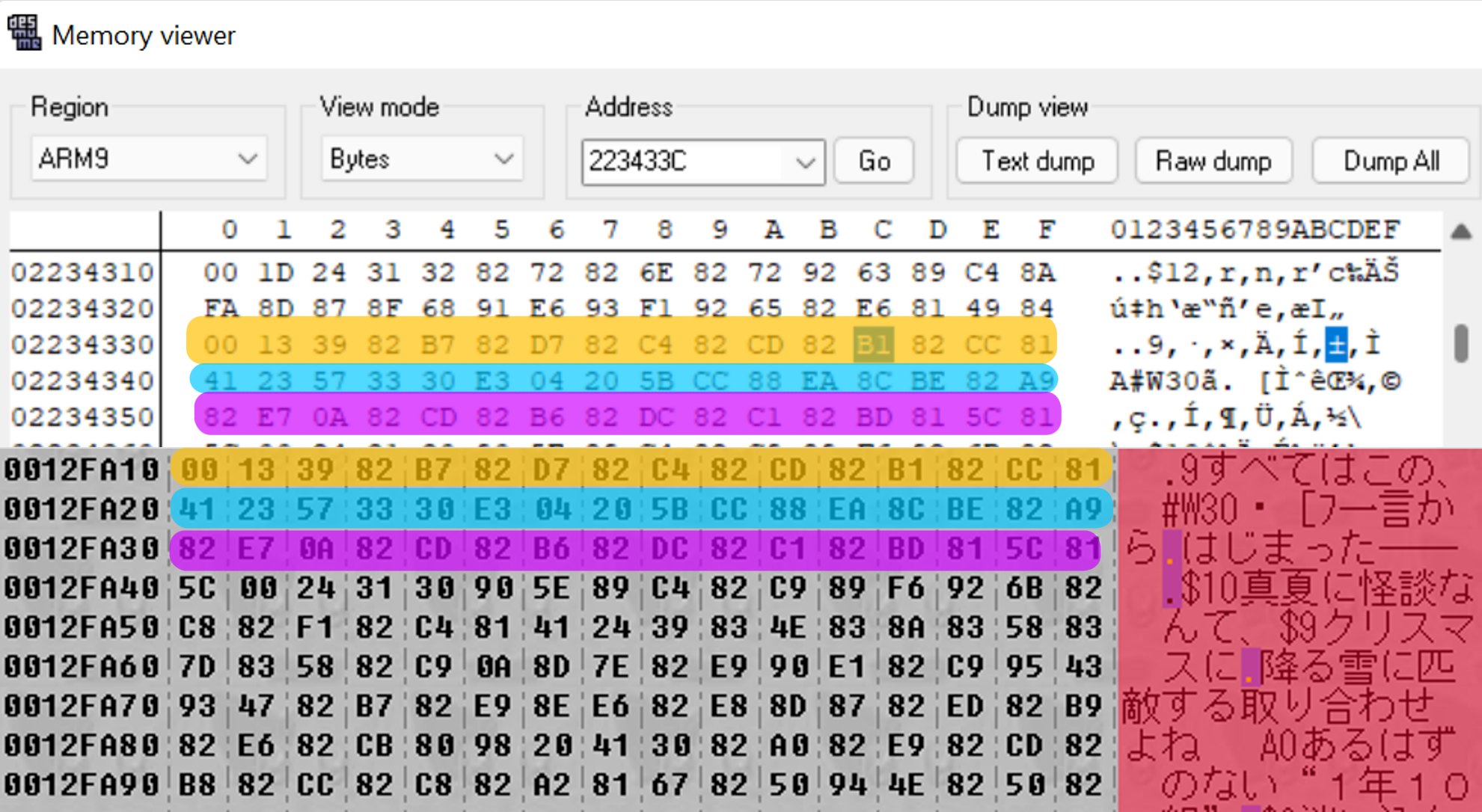
而且这是一处完全匹配!我们已经找到了压缩后的文件被加载到内存中的位置。所以现在,是时候打开最糟糕、但也是唯一一个有函数调试器的 DS 模拟器了——NO$GBA。
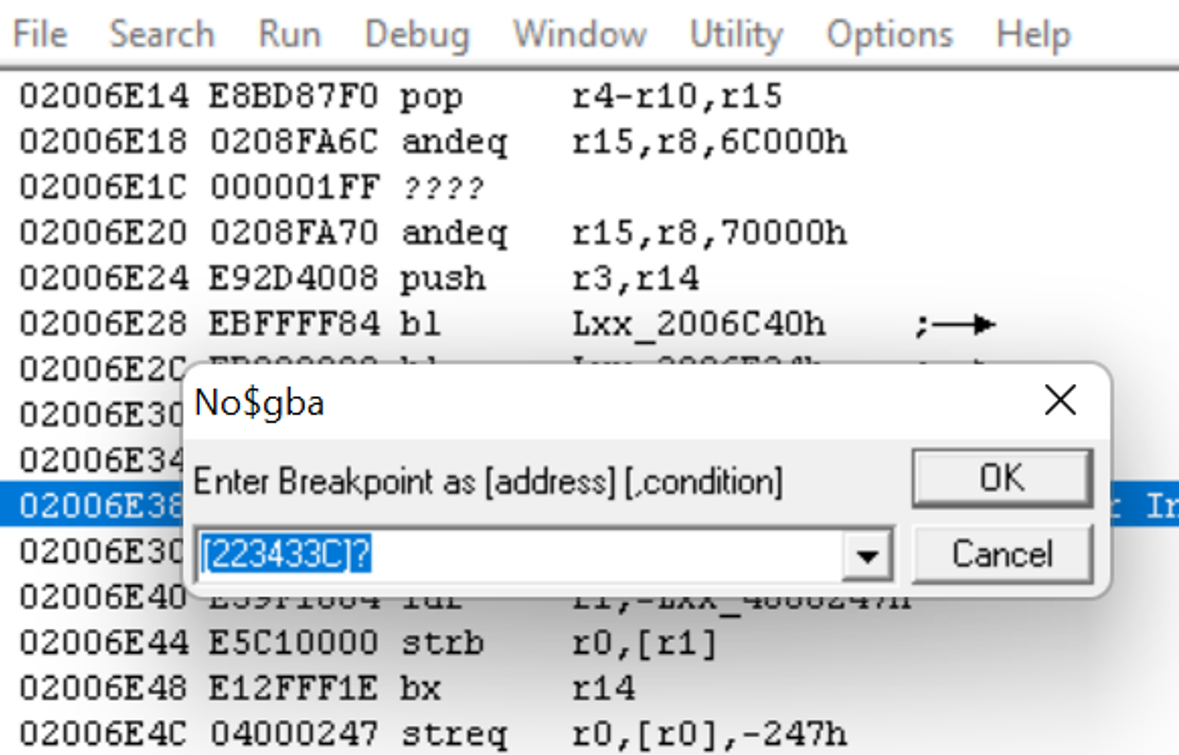
我们将为 0x0223433C 设置一个读取断点。正如我前面提到的,我们之所以使用 NO$GBA,是因为它有一个调试器,而调试器的功能之一是能够设置断点。调试器允许我们在玩游戏时逐步查看正在执行的代码,而断点会告诉调试器在某一行执行时停止。在这种情况下,当游戏从内存地址 0x0223433C 读取内容时,这个读取断点会告诉调试器暂停执行。我们之所以要这样做,是因为游戏对已压缩的文件进行解压缩的时候,会在内存中读取它,所以这将帮助我们找到解压缩子程序。
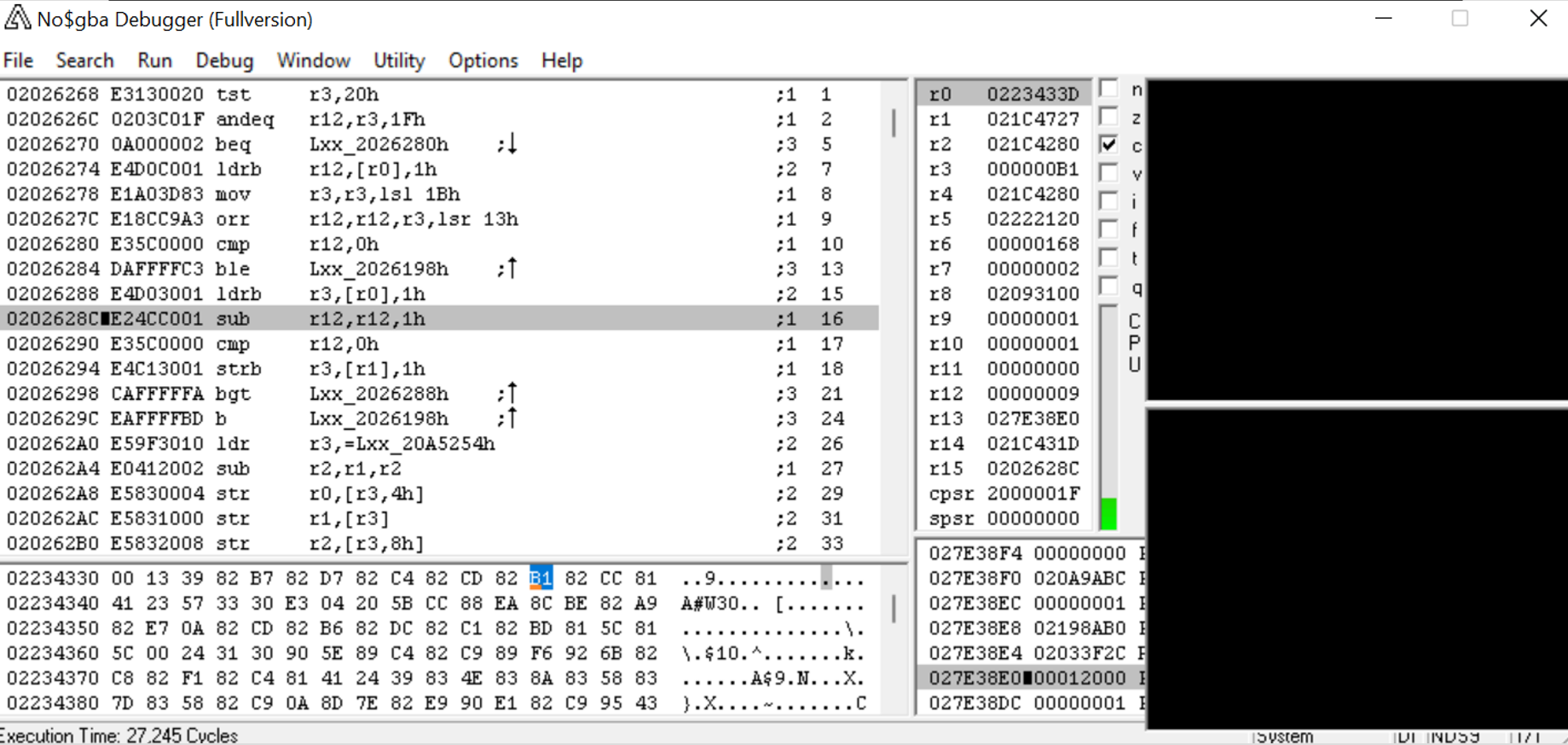
瞧,我们已经到达了断点。游戏按照 0x2026288 的指令从 0x223433C 处读取。是时候打开我们的第三个程序——IDA(交互式反汇编器)了。(值得注意的是,虽然我使用 IDA,但你可以在 Ghidra 中完成同样的事情。Ghidra 是另一个常用的反汇编程序,而且它是免费的。)
因此,在 IDA 中,我们使用 NDS 加载插件来反汇编《串联》的 ROM,这样我们就可以更容易地查看汇编代码(准确来说应该称之为“反汇编”)。IDA 做了一件非常好的事情,那就是它将代码分解为子程序(有时也称为“函数”),这使得代码执行的开始和停止位置一目了然。

所以我们前往这个找到的地址……
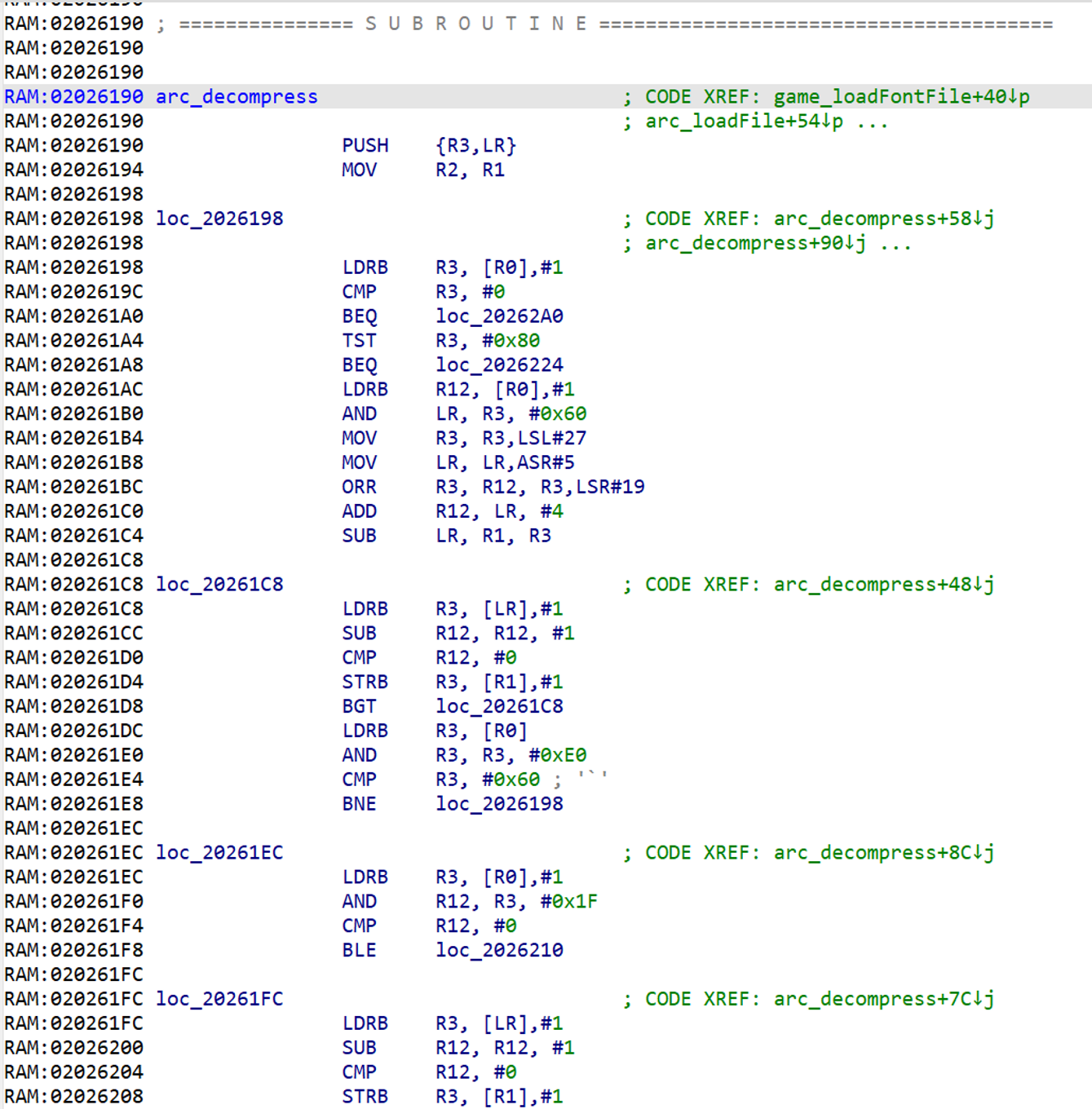
我们找到了!当程序被编译时,函数和变量等所有名称都会被删除,因此 IDA 默认情况下会将子程序命名为类似 sub_2026190 的名字——然而,我们手动将此子程序重命名为 arc_decompression(在屏幕截图中,我们已经完成了),这样更容易找到和引用。(这里的 arc 代表 archive(归档文件)——但我们必须把它留给本系列的下一篇文章。)
这就是我所说的解压缩子程序位于 0x2026190 的意思——只要向上滚动,我们就会发现子程序从那个地址开始。这是我回复 Cerber 的帖子时所得到的,但这也是真正有趣的开始——现在是时候对压缩算法进行逆向工程了。
对压缩算法进行逆向工程
我做的第一件事是创建一个“汇编模拟器”——我将汇编指令一行接一行地反汇编,并移植到 C# 程序中。(在这里,我选择使用 C# 只是因为它是我最熟悉的高级语言;你可以选择使用 Python、C++、JavaScript 或其他你喜欢的语言。)为什么要这样做?当时,我是汇编的初学者,所以这样做有两个目的:首先,这帮助我更加熟悉汇编;其次,这使我拥有了一个可以运行的程序,我知道它与汇编代码所做的事情是匹配的。
这个模拟器最终看起来是这样的:
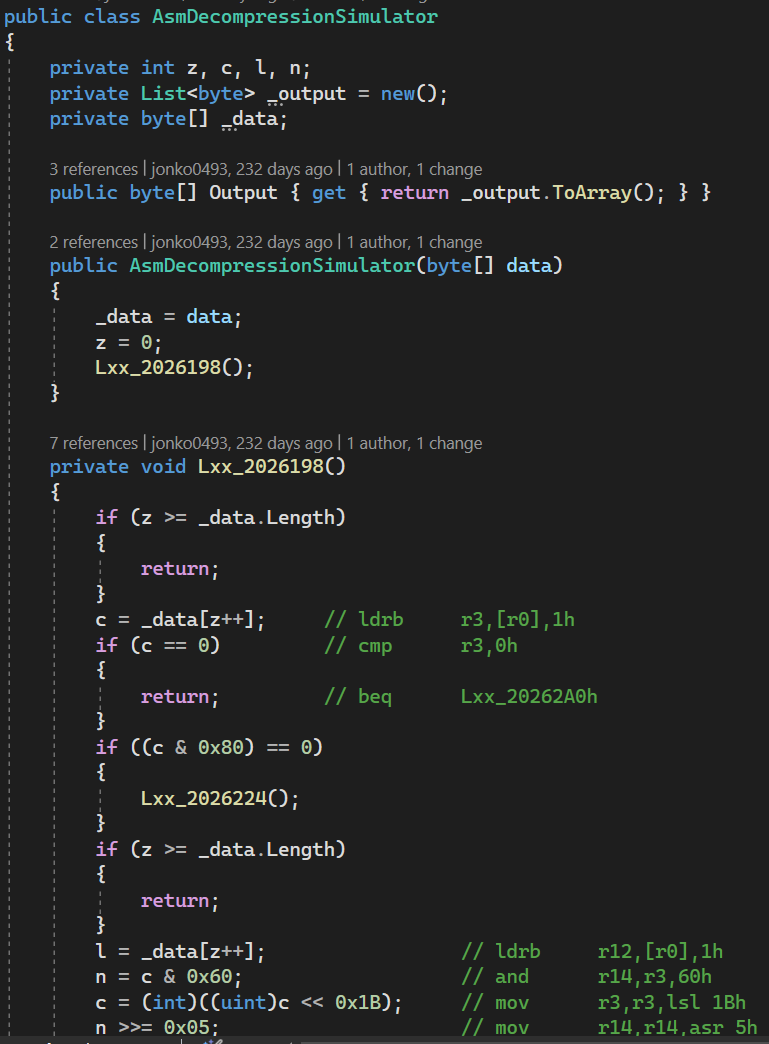
为了便于参考,我对代码行添加了注释,以显示它们在反汇编中对应的指令。完成后,我就可以单纯地解压缩文件了!然而,它的效率相当低。因此,我尝试理解汇编语句,以便将其转化为真正的人类可读的代码。
汇编入门
为了做到这一点,需要了解关于汇编的入门知识:汇编是机器级别的代码,这意味着它是处理器实际读取以执行指令的内容。最后半句话很重要——汇编中最基本的单元是指令。例如,ADD(将两个数字相加)或 SUB(将两个数字相减)。
若要用汇编对值进行操作,必须首先将它们加载到寄存器中。寄存器可以被认为是“CPU变量”,它们拥有例如 R0、R1、R2 之类的编号。DS 有 15 个寄存器。这些值从内存(或者称为 RAM)加载到寄存器中,前者是一个大空间的可快速访问的二进制文件,CPU 可以随时引用。
汇编代码因平台而异——更具体地说,它因微芯片的架构(可以将其视为家族或类型)而异。DS 使用 ARM 指令集作为其主要可执行文件,这是一种常见且拥有详细文档的指令集。我学习 ARM 汇编的方法是直接进入并调试 Nintendo DS 代码,同时在另一个窗口中查找每条指令的作用。如果你正在寻找 ARM 的参考资料,我认为官方文档很有启发性,尽管我也发现在谷歌上搜索“ARM [想要理解的指令]”会产生奇迹。
深入其中
开始
让我们从头开始:
RAM:02026198 LDRB R3, [R0],#1
RAM:0202619C CMP R3, #0
RAM:020261A0 BEQ loc_20262A0
RAM:020261A4 TST R3, #0x80
RAM:020261A8 BEQ loc_2026224
让我们分解一下这些说明:
LDRB R3, [R0], #1——这将 R0 中包含的地址(这包含了文件中的当前位置)处的字节加载到寄存器 R3 中,然后将 R0 增加 1(意味着我们移动到文件中下一个字节的位置)。由于我们处于文件的开头,因此这将加载文件中的第一个字节。CMP R3, #0、BEQ loc_20262A0——BEQ的意思是“如果相等则跳转分支”,但实际上它只是指“如果最后一次比较等于 0 则跳转分支”。因此,如果我们刚刚加载的值为 0,我们将跳转到子程序的末尾。我们现在可以忽略这一点。TST R3, #0x80——TST执行按位与且不存储结果。按位与比较两个字节,并给出一个结果,其中只有当某个位(bit)在其比较的两个字节对应的位都是 1 时才为 1。在 R3 为 0xAA 的情况下,我们最终得到如下结果:
10101010 (0xAA)
10000000 (0x80)
_______
10000000 (0x80)
因此,这个 BEQ 后面跟着的 TST 只是在检查第一个位是否为 0。如果它为 0,我们将会跳转到 0x2026224。让我们现在跳转在那里(我知道一些你不知道的事,所以我知道检查这个分支会更简单,哈哈)。但首先,我们将把它转换成 C#:
int blockByte = compressedData[z++];
if (blockByte == 0)
{
break;
}
if ((blockByte & 0x80) == 0)
{
// 做某些事
}
else
{
// 做另一些事
}
到目前为止非常简单——我们只是检查第一个位是否为零。
直接写入
RAM:02026224 TST R3, #0x40
RAM:02026228 BEQ loc_2026268
TST R3, #0x40——现在检查第 2 位是否为 1。如果是,我们将跳转到 0x2026268。我们稍后再回到这一节,但首先让我们将其转换为 C# 后跳转到那里:
if ((blockByte & 0x80) == 0)
{
if ((blockByte & 0x40) == 0)
{
// 做某些事 0x80
}
else
{
// 做另一些事 0x80
}
}
else
{
// 做另一些事
}
RAM:02026268 loc_2026268 ; CODE XREF: arc_decompress+98↑j
RAM:02026268 TST R3, #0x20
RAM:0202626C ANDEQ R12, R3, #0x1F
RAM:02026270 BEQ loc_2026280
RAM:02026274 LDRB R12, [R0],#1
RAM:02026278 MOV R3, R3,LSL#27
RAM:0202627C ORR R12, R12, R3,LSR#19
RAM:02026280
RAM:02026280 loc_2026280 ; CODE XREF: arc_decompress+E0↑j
RAM:02026280 CMP R12, #0
RAM:02026284 BLE loc_2026198
RAM:02026288
RAM:02026288 loc_2026288 ; CODE XREF: arc_decompress+108↓j
RAM:02026288 LDRB R3, [R0],#1
RAM:0202628C SUB R12, R12, #1
RAM:02026290 CMP R12, #0
RAM:02026294 STRB R3, [R1],#1
RAM:02026298 BGT loc_2026288
RAM:0202629C B loc_2026198
这是一个相当大的代码块,但不要被吓到。我们得到了这些:
TST R3, #0x20、ANDEQ R12, R3, #0x1F——现在我们在这里测试第 1 个字节的第 3 位。如果它为 0,我们将取其最后 5 位(0x1F = 0xb0001_1111),并跳转到分支 0x2026280。我们稍后去那里。LDRB R12, [R0], #1——我们正在将文件中的下一个字节加载到寄存器(R12)中。因此,如果第 1 个字节的第 3 位为 1,就意味着我们需要对下一个字节做些什么。MOV R3, R3, LSL#27、ORR R12, R12, R3, LSR#19——LSL是“逻辑左移”,LSR是“逻辑右移”,分别表示将 R3 中的位向左或向右移动 27 位和 19 位。将它们向左移 27 位和向右移 19 位意味着在清除前 3 位之后向左移 8 位,这相当于将“R3 & 0x1F”乘以 0x100。使用按位或,我们将刚读取的第一个字节和第二个字节组合成一个 16 位整数。
这是在 if 语句中计算一些东西——我们可以在 C# 中这样表示:
int value;
if ((blockByte & 0x20) == 0)
{
value = blockByte; // `&0x1F` 是不必要的,因为我们已经确定第 1-3 位为 0
}
else
{
// 第 3 位 == 1 --> 需要两个字节来指示要读取的数据量
value = compressedData[z++] + ((blockByte & 0x1F) * 0x100);
}
我们还不清楚这个值的确切作用,但当我们看下一节时,这一点会变得很清楚。
CMP R12, #0、BLE loc_2026198——如果我们刚刚计算的值为 0,我们立即返回到函数的顶部。LDRB R3, [R0], #1——正如我们现在习惯的那样,我们把下一个字节加载到 R3 。SUB R12, R12, #1——我们从前面计算的值中减去 1。CMP R12, #0——我们将前面计算的值与 0 进行比较。STRB R3, [R1], #1——我们将刚刚读取的最新值存储在解压缩的数据缓冲区中,并在该缓冲区中向前移动一个值。BGT loc_2026288——如果两步前得到的 R12 大于0,我们将转到本节的第一步。啊哈——这是一个循环!B loc_2026198——如果它小于或等于 0,我们回到子程序的顶部。
这实际上非常简单,因为我们知道这是一个循环。我们前面计算的 value 实际上是要直接从输入缓冲区复制到输出缓冲区的字节数(numBytes)。因此,我们可以将该部分表示为:
for (int i = 0; i < numBytes; i++)
{
decompressedData.Add(compressedData[z++]);
}
更重要的是,我们每次返回函数顶部的事实意味着它也是一个循环。
到目前为止,我们编写的程序如下所示:
for (int z = 0; z < compressedData.Length;)
{
int blockByte = compressedData[z++];
if (blockByte == 0)
{
break;
}
if ((blockByte & 0x80) == 0)
{
if ((blockByte & 0x40) == 0)
{
// 第 1 & 2 位 == 0 --> 直接读取数据
int numBytes;
if ((blockByte & 0x20) == 0)
{
numBytes = blockByte; // `&0x1F` 是不必要的,因为我们已经确定第 1-3 位为 0
}
else
{
// 第 3 位 == 1 --> 需要两个字节来指示要读取的数据量
numBytes = compressedData[z++] + ((blockByte & 0x1F) * 0x100);
}
for (int i = 0; i < numBytes; i++)
{
decompressedData.Add(compressedData[z++]);
}
}
解压文件
因此,解压算法的基本操作如下:读入一个“控制字节”,其前 3-4 位决定以下功能。解压缩选项包括:
- 将一定数量的字节直接读入解压缩的缓冲区
- 读取单个字节并重复一定次数
- 逆向引用解压缩数据中的特定位置,并复制这些字节
完整的解压缩实现可以在这里找到。
如果我们尝试解压缩文件……

这就是解压缩的脚本!好极了。
创建压缩程序
现在我们很好地理解了解压缩算法,可以解压缩所有文件,用英语文本替换日语文本。但如果我们想将它们重新插入游戏,我们仍然需要重新压缩编辑过的文件。因此,我们必须实现一个压缩程序。我们不能像解压缩子程序那样从程序集中复制一个,因为该程序不在游戏中(文件在游戏创建时被压缩,它们只在游戏中被解压缩)。但这并没有那么糟糕——既然我们知道解压缩是如何工作的,我们只需要扭转这个过程来压缩东西。
例如,我们可以很容易地实现“直接写入”模式:
private static void WriteDirectBytes(byte[] writeFrom, List<byte> writeTo, int position, int numBytesToWrite)
{
if (numBytesToWrite < 0x20)
{
writeTo.Add((byte)numBytesToWrite);
}
else
{
int msb = 0x1F00 & numBytesToWrite;
byte firstByte = (byte)(0x20 | (msb / 0x100));
byte secondByte = (byte)(numBytesToWrite - msb);
writeTo.AddRange(new byte[] { firstByte, secondByte });
}
writeTo.AddRange(writeFrom.Skip(position - numBytesToWrite).Take(numBytesToWrite));
}
首先,我们获取要写入的字节数。如果该数字小于 0x20(即可以包含在控制字节的低 5 位中),那么我们只需将该数字写入输出缓冲区。否则,我们必须计算要写入的两个字节来表示更大的数字。最后,我们简单地将字节写入输出缓冲区。
我们可以为重复模式和逆向引用模式实现类似(尽管更复杂)的功能。最终结果可以在此处找到。
下一步是什么
现在,我们已经实现了压缩和解压缩,但我们还没有脱离困境。接下来,我们必须面对这样一个事实,即这个文件只是归档文件中众多文件中的一个,我们必须找出如何正确地替换它。请阅读我们的下一篇文章,我们将深入研究它。